Top News
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
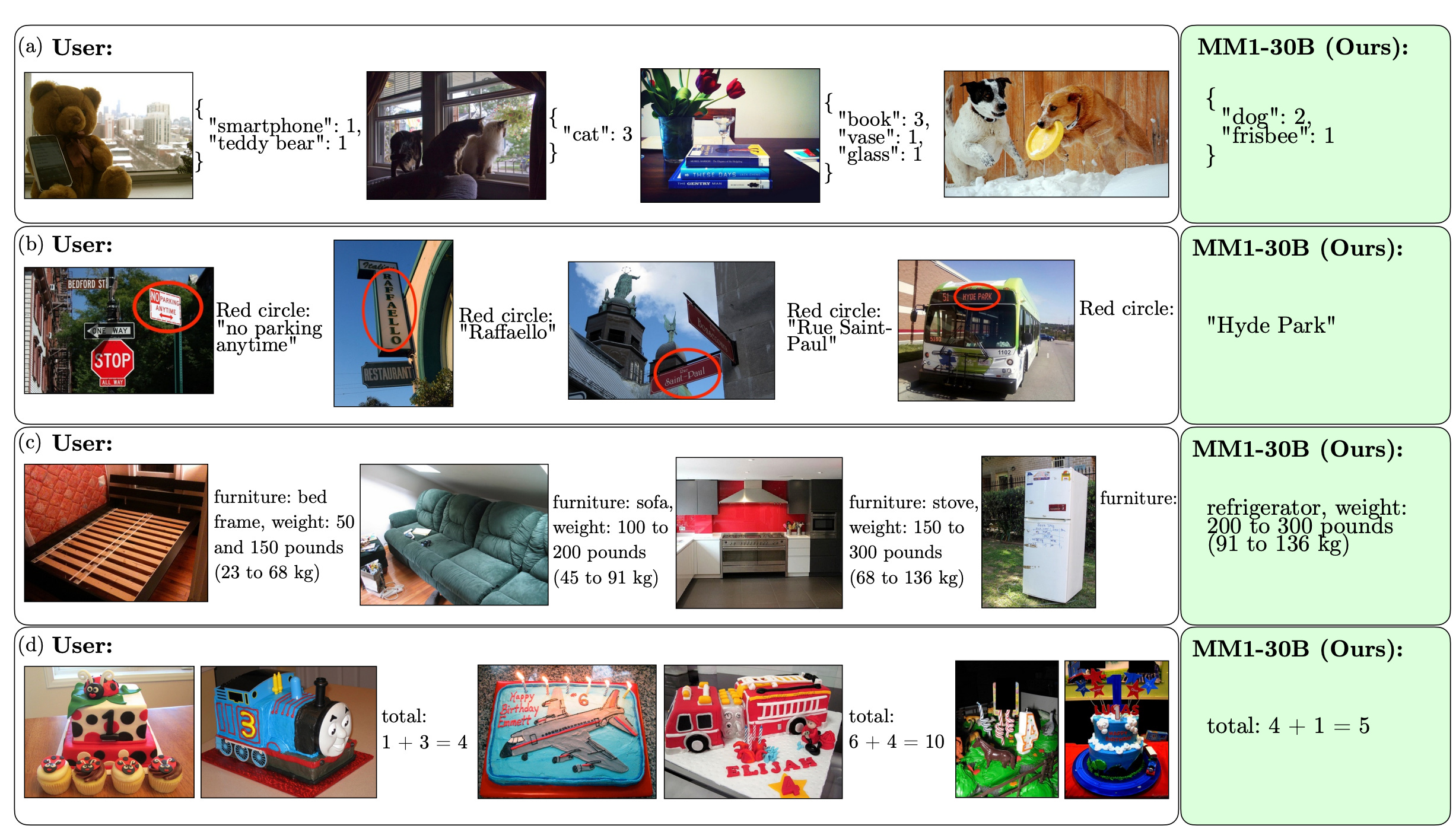
Apple released a paper detailing its efforts in training Multimodal Large Language Models (MLLMs), focusing on the significance of different architecture components and data choices. The authors found that a balanced mix of image-caption, interleaved image-text, and text-only data is essential for achieving state-of-the-art (SOTA) results in large-scale multimodal pre-training. They also discovered that the image encoder, image resolution, and image token count have a significant impact, while the design of the vision-language connector is less important. The authors then present MM1, a family of multimodal models with up to 30 billion parameters, including both dense models and mixture-of-experts (MoE) variants. These models demonstrate superior pre-training metrics and competitive performance after supervised fine-tuning on various multimodal benchmarks.
Cerebras Unveils Its Next Waferscale AI Chip

Cerebra has introduced the Wafer Scale Engine 3 (WSE-3). It’s the world's largest single chip, boasts 4 trillion transistors—a more than 50% increase over its predecessor—achieved through the adoption of cutting-edge 5-nanometer technology from TSMC. This advancement allows the chip to double its performance without increasing power consumption, enabling it to power a new generation of AI supercomputers, including the soon-to-be-completed 8-exaflop (8 billion billion operations per second) supercomputer in Dallas. The CS-3 computer, utilizing WSE-3 chips, is designed to train exceptionally large neural network models, up to 24 trillion parameters in size, which is more than 10 times the capability of today's largest language models like OpenAI's GPT-4. Additionally, Cerebras has announced a partnership with Qualcomm aimed at reducing the cost of AI inference by a factor of ten, potentially revolutionizing the accessibility and sustainability of AI technologies.
Microsoft hires DeepMind co-founder Mustafa Suleyman to run new consumer AI unit

Microsoft has announced the hiring of Mustafa Suleyman, co-founder of Google’s DeepMind and CEO of the AI startup Inflection, to lead a new consumer AI unit within the company, named Microsoft AI. This move aims to strengthen Microsoft's position in the generative AI market by integrating its consumer-facing products under Suleyman's leadership. The new unit will focus on incorporating AI technologies into Microsoft’s products, including an AI-enhanced version of Copilot for Windows and improving Bing’s search engine with generative AI capabilities. The recruitment also includes some key members of Inflection’s team, including key figures like Karén Simonyan as chief scientist.
Stability AI CEO resigns to ‘pursue decentralized AI’

Emad Mostaque, CEO of Stability AI, has resigned from his position to focus on decentralized AI, a move that follows the recent departure of other key developers from the company. In the interim, COO Shan Shan Wong and CTO Christian Laforte will act as co-CEOs while the board searches for a permanent replacement. This leadership change comes amidst a turbulent time in the AI startup world, with rival startup Inflection AI losing key personnel to Microsoft. Despite these challenges, Stability AI continues to develop and commercialize its AI products, including its flagship product, Stable Diffusion, and its latest model, Stable Cascade, while also offering a paid membership for commercial use of its models.
Other News
Tools
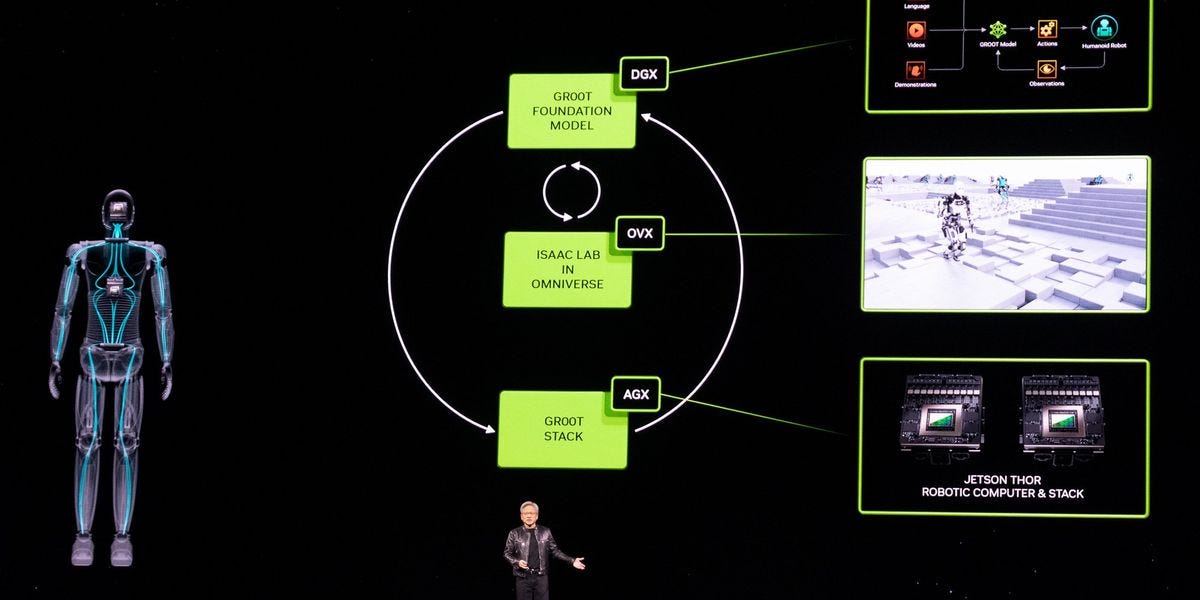
Nvidia Announces GR00T, a Foundation Model For Humanoids - Nvidia introduces GR00T, a foundation model for humanoids, at its GTC developer conference, alongside significant robotics announcements.
Nvidia reveals Blackwell B200 GPU, the ‘world’s most powerful chip’ for AI - Nvidia reveals the Blackwell B200 GPU, offering up to 20 petaflops of FP4 horsepower and 30 times the performance for LLM inference workloads, potentially being substantially more efficient.
Introducing Stable Video 3D: Quality Novel View Synthesis and 3D Generation from Single Images - Introducing Stable Video 3D, a generative model that advances 3D technology by producing high-quality multi-views and 3D meshes from single images, featuring two variants for different applications.
Nvidia is using AI to turn game characters into chatbots - Nvidia's AI "digital human" tools are being used by developers to voice, animate, and generate dialogue for video game characters, allowing for unique player interactions and real-time responses.
Colossal-AI Team Introduces Open-Sora: An Open-Source Library for Video Generation - AI video generation technology is revolutionizing various industries by offering new ways to create and manipulate video content, and the development of Open-Sora marks a significant advancement in the field, providing a cost-effective and efficient solution that broadens the horizons for content creators.
Adobe Substance 3D’s AI features can turn text into backgrounds and textures - Adobe Substance 3D's AI features streamline 3D workflows by using text descriptions to generate photorealistic textures and background images for 3D models.
Google DeepMind’s new AI assistant helps elite soccer coaches get even better - Google DeepMind's TacticAI uses AI to analyze corner kick data from Liverpool FC and provide recommendations for positioning players and predicting outcomes.
Business

Saudi Arabia Plans $40 Billion Push Into Artificial Intelligence - Saudi Arabia plans to invest $40 billion in artificial intelligence, aiming to become the world's largest investor in AI and diversify its economy.
Denmark to build one of the world’s most powerful AI supercomputers, accelerating solutions to societal challenges - Denmark is collaborating with NVIDIA to establish a national centre for AI innovation, housing one of the world’s most powerful AI supercomputers, to accelerate research and innovation in fields from healthcare and life sciences to the green transition.
A wave of drugs dreamed up by AI is on its way - AI is being used to dream up cures for diseases, with companies like Insilico using AI to speed up drug discovery and development, potentially revolutionizing the field of digital biology.
Apple Is in Talks to Let Google Gemini Power iPhone AI Features - Apple is in talks to integrate Google's Gemini AI engine into the iPhone, potentially shaking up the AI industry and introducing new features to the iPhone software.
Apple is adding to its arsenal of AI startups with a little-known Canadian firm - Apple has acquired a Canadian AI startup, DarwinAI, to enhance its AI technology and improve efficiency in its supply chain.
Microsoft to Pay Inflection AI $650 Million After Scooping Up Most of Staff - Microsoft pays $650 million to license Inflection AI's software and hires most of its staff, sparking potential antitrust concerns.
AI already used by 62% of studios, Unity report claims - 62% of game studios are using AI during game development, with AI tools improving delivery and operations, shortening prototyping time, and aiding in world building, while some developers are hesitant due to lack of time or technical knowhow.
Nvidia announces AI-powered health care 'agents' that outperform nurses — and cost $9 an hour - Nvidia and Hippocratic AI have developed AI "agents" that outperform human nurses on video calls, cost significantly less per hour, and are designed to form a human connection with patients through "super-low latency conversational reactions."
Research

How AI taught Cassie the two-legged robot to run and jump - AI taught a two-legged robot to run, jump, and adapt to new scenarios using reinforcement learning, enabling it to perform various dynamic motions without explicit training for each movement.
Algorithmic progress in language models - Language model algorithms have been improving rapidly, with the compute required to reach a performance threshold halving approximately every 8 months, indicating substantial progress in algorithmic development.
MoAI: Mixture of All Intelligence for Large Language and Vision Models - A new large language and vision model, MoAI, leverages auxiliary visual information from external computer vision models to significantly outperform existing models in zero-shot vision language tasks.
Larimar: Large Language Models with Episodic Memory Control - A novel brain-inspired architecture called Larimar enhances Large Language Models with distributed episodic memory, allowing for dynamic, one-shot updates of knowledge without the need for computationally expensive re-training or fine-tuning, resulting in improved accuracy, speed, and flexibility.
MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data - AI model MindEye2 enables high-quality reconstructions of visual perception from fMRI data with only 1 hour of training, using a shared-subject approach across 7 subjects and a novel functional alignment procedure.
mPLUG-DocOwl 1.5: Unified Structure Learning for OCR-free Document Understanding - mPLUG-DocOwl 1.5 introduces Unified Structure Learning to enhance the performance of Multimodal Large Language Models in understanding text-rich document images, achieving state-of-the-art results on 10 visual document understanding benchmarks.
LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression - A new approach to prompt compression using data distillation and token classification achieves efficient and faithful compression, leading to significant performance gains and faster processing times.
Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking - Language models can learn to generate rationales to explain future text, improving their predictions and reasoning abilities, without the need for fine-tuning on specific tasks.
PERL: Parameter Efficient Reinforcement Learning from Human Feedback - Parameter Efficient Reinforcement Learning (PERL) uses Low-Rank Adaptation (LoRA) to train models, enabling high performance while reducing computational burden, and is compared to conventional RLHF settings across various configurations for 7 benchmarks.
VideoAgent: Long-form Video Understanding with Large Language Model as Agent - A novel agent-based system, VideoAgent, utilizes a large language model to iteratively identify and compile crucial information from long-form videos, achieving superior effectiveness and efficiency in long-form video understanding.
One-Step Image Translation with Text-to-Image Models - Adapting a single-step diffusion model to new tasks and domains through adversarial learning objectives, the article introduces a method for image translation that outperforms existing GAN-based and diffusion-based methods for various scene translation tasks.
Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation - A novel distillation approach called Latent Adversarial Diffusion Distillation (LADD) enhances the performance of image synthesis models, enabling high-resolution multi-aspect ratio image synthesis with fast inference speed.
MusicHiFi: Fast High-Fidelity Stereo Vocoding - Efficient high-fidelity stereophonic vocoder MusicHiFi proposed, employing a cascade of three generative adversarial networks to convert low-resolution mel-spectrograms to audio, upsample to high-resolution audio, and upmix to stereophonic audio, yielding better audio quality and faster inference speed.
LATTE3D - Amortized methods like ATT3D optimize multiple prompts simultaneously to improve efficiency, enabling fast text-to-3D synthesis, but LATTE3D addresses limitations to achieve fast, high-quality generation on a significantly larger prompt set.
DROID: A Large-Scale In-the-Wild Robot Manipulation Dataset - A large-scale robot manipulation dataset called DROID is introduced, featuring a comprehensive list of authors and contributors.
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference - An open platform called Chatbot Arena uses crowdsourcing to evaluate Large Language Models based on human preferences, amassing over 240K votes and gaining credibility among LLM developers and companies.
VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis - A method called VLOGGER is proposed for audio-driven human video generation from a single input image, utilizing a stochastic human-to-3d-motion diffusion model and a novel diffusion-based architecture to generate high-quality videos with spatial and temporal controls.
AI-Generated Science - AI-generated science papers are being published by academic journals, featuring the ChatGPT phrase "As of my last knowledge update."
Concerns
OpenAI’s chatbot store is filling up with spam - OpenAI's GPT Store is facing issues with spam, copyright infringement, academic dishonesty, impersonation, and attempts to jailbreak OpenAI's models, raising concerns about the quality and legality of the GPTs available.
Nearly 4,000 celebrities found to be victims of deepfake pornography - AI-generated deepfake pornography is a widespread issue affecting thousands of celebrities, with legislation in the UK aiming to address the problem.
Among the A.I. Doomsayers - A researcher in the Bay Area explores the potential dangers of artificial intelligence, hosting dinner parties for like-minded individuals and engaging in speculative conversations about the existential risks posed by A.I.
Policy

DHS unveils new AI roadmap - DHS launches AI roadmap to guide federal operations, focusing on responsible AI use, national safety and security, and public-private partnerships, with three pilot programs announced to inform department-wide policies.
Africa’s push to regulate AI starts now - African Union is preparing an ambitious AI policy to regulate the technology's development and use in member nations, with some countries already formulating their own legal and policy frameworks for AI.
States are racing ahead of Congress to regulate deepfakes - States are taking the lead in regulating deepfakes, particularly in the areas of politics and pornography, with at least 15 states passing laws to address the issue, while federal lawmakers are proposing various bills to create a standard across all fifty states.
Chinese platforms are cracking down on influencers selling AI lessons - Chinese social platforms crack down on influencers selling superficial and overpriced AI lessons, leading to the removal of their content and suspension of their accounts.
Fun

10 of My Most Popular Text-To-Image Series (+Prompts) - Experimenting with text-to-image models, the author shares their 10 most popular AI image series and the simple prompts used to generate them, advocating for a less-is-more approach and emphasizing the fun in creating AI-generated images.
Copyright © 2024 Skynet Today, All rights reserved.