For data scientists and ML engineers, building analysis and models in Python is almost second nature, and Python’s popularity in the data science community has only skyrocketed with the recent generative AI boom. We believe that the future of data science is no longer just about neatly organized rows and columns. For decades, many valuable insights have been locked in images, audio, text, and other unstructured formats. And now, with the advances in gen AI, data science workloads must evolve to handle multi-modality and use new gen AI and agentic techniques.
To prepare you for the data science of tomorrow, we announced BigQuery DataFrames 2.0 last week at Google Cloud Next 25, bringing multimodal data processing and AI directly into your BigQuery Python workflows.

Extending Pandas DataFrames for BigQuery Multimodal Data
In BigQuery, data scientists frequently look to use Python to process large data sets for analysis and machine learning. However, this almost always involves learning a different Python framework and rewriting the code that worked on smaller data sets. You can hardly take Pandas code that worked on 10 GB of data and get it working for a terabyte of data without expending significant time and effort.
Version 2.0 also strengthens the core foundation for larger-scale, Python data science. And then it builds on this foundation, adding groundbreaking new capabilities that unlock the full potential of your data, both structured and unstructured.
- aside_block
- <ListValue: [StructValue([('title', '$300 in free credit to try Google Cloud data analytics'), ('body', <wagtail.rich_text.RichText object at 0x3e76b8755640>), ('btn_text', 'Start building for free'), ('href', 'http://console.cloud.google.com/freetrial?redirectPath=/bigquery/'), ('image', None)])]>
BigQuery DataFrames adoption
We launched BigQuery DataFrames last year as an open-source Python library that scales Python data processing without having to add any new infrastructure or APIs, transpiling common Python data science APIs from Pandas and scikit-learn to various BigQuery SQL operators. Since its launch, there’s been over 30X growth in how much data it processes and, today, thousands of customers use it to process more than 100 PB every month.
During the last year we evolved our library significantly across 50+ releases and worked closely with thousands of users. Here’s how a couple of early BigQuery DataFrames customers use this library in production.
Deutsche Telekom has standardized on BigQuery DataFrames for its ML platform.
“With BigQuery DataFrames, we can offer a scalable and managed ML platform to our data scientists with minimal upskilling.” - Ashutosh Mishra, Vice President - Data Architecture & Governance, Deutsche Telekom
Trivago, meanwhile, migrated its PySpark transformations to BigQuery DataFrames.
“With BigQuery DataFrames, data science teams focus on business logic and not on tuning infrastructure.” - Andrés Sopeña Pérez, Head of Data Infrastructure, Trivago
What's new in BigQuery Dataframes 2.0?
This release is packed with features designed to streamline your AI and machine learning pipelines:
Working with multimodal data and generative AI techniques
-
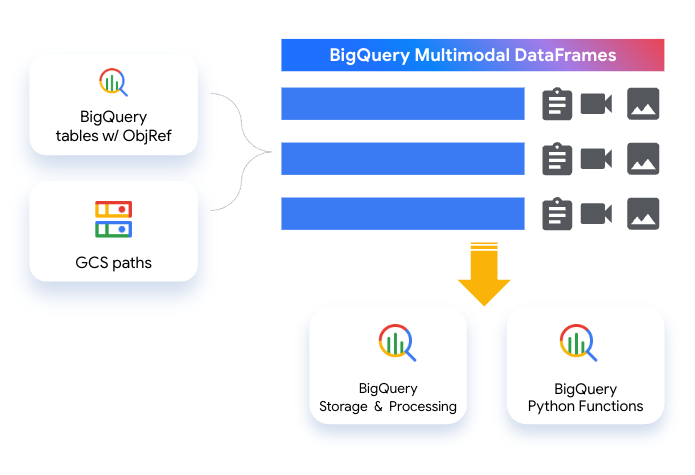
Multimodal DataFrames (Preview): BigQuery Dataframes 2.0 introduces a unified dataframe that can handle text, images, audio, and more, alongside traditional structured data, breaking down the barriers between structured and unstructured data. This is powered by BigQuery’s multimodal capabilities enabled by ObjectRef, helping to ensure scalability and governance for even the largest datasets.
When working with multimodal data, BigQuery DataFrames also abstracts many details for working with multimodal tables and processing multimodal data, leveraging BigQuery features behind the scene like embedding generation, vector search, Python UDFs, and others.
-
Pythonic operators for BigQuery AI Query Engine (experimental): BigQuery AI Query Engine makes it trivial to generate insights from multimodal data: Now, you can analyze unstructured data simply by including natural language instructions in your SQL queries. Imagine writing SQL queries where you can rank call transcripts in a table by ‘quality of support’ or generate a list of products with ‘high satisfaction’ based on reviews in a column. BigQuery AI Query Engine makes that possible with simple, stackable SQL.
BigQuery DataFrames offers a DataFrame interface to work with AI Query Engine. Here’s a sample:
- code_block
- <ListValue: [StructValue([('code', 'import bigframes.pandas as bpd\r\n\r\nfrom bigframes.ml import llm \r\ngemini_model = llm.GeminiTextGenerator(model_name="gemini-1.5-flash-002")\r\n\r\n# Get Top K products with higher satisfacton \r\ndf = bpd.read_gbq("project.dataset.transcripts_table")\r\nresult = df.ai.top_k("The reviews in {review_transcription_col} indicates higher satisfaction", model=gemini_model)\r\n\r\n# Works with multimodal data as well. \r\ndf = bpd.from_glob_path("gs://bucket/images/*", name="image_col")\r\nresult = df.ai.filter("The main object in the {image_col} can be seen in city streets", model=gemini_model)'), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e76be577970>)])]>
-
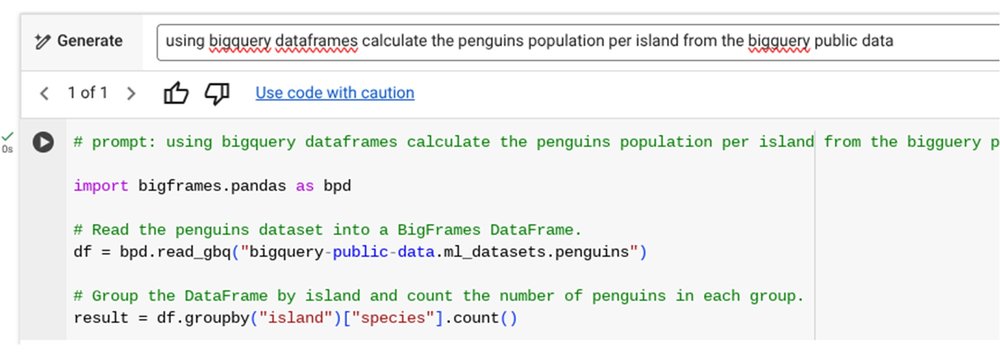
Gemini Code Assist for DataFrames (Preview): To keep up with the evolving user expectations around code generation, we’re also making it easier to develop BigQuery DataFrames code, using natural language prompts directly within BigQuery Studio. Together, Gemini's contextual understanding and DataFrames-specific training help ensure smart, efficient code generation. This feature is released as part of Gemini in BigQuery.
Strengthening the core
To make the core Python data science workflow richer and faster to use, we added the following features.
-
Partial ordering (GA): By default, BigQuery DataFrames maintains strict ordering (as does Pandas). With 2.0, we’re introducing a relaxed ordering mode that significantly improves performance, especially for large-scale feature engineering. This "spin" on traditional Pandas ordering is tailored for the massive datasets common in BigQuery. Read more about partial ordering here.
Here’s some example code that uses partial ordering :
- code_block
- <ListValue: [StructValue([('code', 'import bigframes.pandas as bpd\r\nimport datetime\r\n\r\n# Enable the partial ordering mode\r\nbpd.options.bigquery.ordering_mode = "partial"\r\n\r\npypi = bpd.read_gbq("bigquery-public-data.pypi.file_downloads")\r\n\r\n# Show a preview of the previous day\'s downloads.\r\n# The partial ordering mode is 4,000,000+ more efficient in terms of billed bytes.\r\nlast_1_days = datetime.datetime.now(datetime.timezone.utc) - datetime.timedelta(days=1)\r\nbigframes_downloads = pypi[(pypi["timestamp"] > last_1_days) & (pypi["project"] == "bigframes")]\r\nbigframes_downloads[["timestamp", "project", "file"]].peek()'), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e76be577640>)])]>
-
Work with Python UDF (Preview): BigQuery Python user-defined functions are now available in preview [see the documentation].
Within BigQuery DataFrames you can now auto-scale Python function execution to millions of rows, with serverless, scale-out execution. All you need to do is put a “@udf” decorator on top of a function that needs to be pushed to the server-side.
Here is an example code that tokenizes comments from stackoverflow data stored in a BigQuery public table with ~90 million rows using a Python UDF:
- code_block
- <ListValue: [StructValue([('code', 'import bigframes.pandas as bpd\r\n\r\n# Auto-create the server side Python UDF\r\[email protected](packages=["tokenizer"])\r\ndef get_sentences(text: str) -> list[str]:\r\n from tokenizer import split_into_sentences \r\n return list(split_into_sentences(text))\r\n\r\ndf = bpd.read_gbq(\r\n "bigquery-public-data.stackoverflow.comments"\r\n)\r\n# Invoke the Python UDF\r\nresult = df["text"].apply(get_sentences)\r\nresult.peek()'), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e76be577910>)])]>
- dbt Integration (Preview): For all the dbt users out there, you can now integrate BigQuery DataFrames Python into your existing dbt workflows. The new dbt Python model allows you to run BigQuery DataFrames code alongside your BigQuery SQL, unifying billing, and simplifying infrastructure management. No new APIs or infrastructure to learn — just the power of Python and BigQuery DataFrames within your familiar dbt environment. [Try now ]
- code_block
- <ListValue: [StructValue([('code', 'import bigframes.pandas as bpd\r\nimport holidays\r\n\r\ndef model(dbt, session):\r\n dbt.config(submission_method="bigframes")\r\n\r\n data = {\r\n \'id\': [0, 1, 2],\r\n \'name\': [\'Brian Davis\', \'Isaac Smith\', \'Marie White\'],\r\n \'birthday\': [\'2024-03-14\', \'2024-01-01\', \'2024-11-07\']\r\n }\r\n bdf = bpd.DataFrame(data)\r\n\r\n bdf[\'birthday\'] = bpd.to_datetime(bdf[\'birthday\'])\r\n bdf[\'birthday\'] = bdf[\'birthday\'].dt.date\r\n us_holidays = holidays.US(years=2024)\r\n\r\n return bdf[bdf[\'birthday\'].isin(us_holidays)]'), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e76be577610>)])]>
Why this matters now
For years, unstructured data has largely resided in silos, separate from the structured data in data warehouses. This separation restricted the ability to perform comprehensive analysis and build truly powerful AI models. BigQuery’s multimodal capabilities and BigQuery Dataframes 2.0 eliminates this divide, bringing the capabilities traditionally associated with data lakes directly into the data warehouse, enabling:
-
Unified data analysis: Analyze all your data – structured and unstructured – in one place, using a single, consistent Pandas-like API.
-
LLM-powered insights: Unlock deeper insights by combining the power of LLMs with the rich context of your structured data.
-
Simplified workflows: Streamline your data pipelines and reduce the need for complex data movement and transformation.
-
Scalability and governance: Leverage BigQuery's serverless architecture and robust governance features for all your data, regardless of format.
See BigQuery Dataframes 2.0 in Action
You can see all of these features in action in this video from Google Cloud Next ’25
Get started today!
BigQuery Dataframes 2.0 is a game-changer for anyone working with data and AI. It's time to unlock the full potential of your data, regardless of its structure. Start experimenting with the new features today!
- Dive into the documentation.
-
For multimodal use cases - fill out this intake form to get your project number allowlisted for ObjectRef.
-
Try out DBT Python model with BigQuery DataFrames via this Quickstart
-
Join the Community - Stay connected with the BigQuery DataFrames team by signing up for an email group here.