Retrieval-augmented generation (RAG) combines the power of large language models with real-time information retrieval, making AI responses more accurate and context-aware. In this guide, we'll walk you through building a RAG system using Anthropic Claude and PostgreSQL on Amazon Bedrock. If you're already using AWS and are a PostgreSQL enthusiast exploring scalable AI solutions, this tutorial will help you enhance your application's intelligence with minimal infrastructure overhead.
Understanding Retrieval-Augmented Generation (RAG)
Retrieval-augmented generation (RAG) is a powerful technique that enhances AI-generated text by pulling in relevant data snippets from a database. Instead of relying solely on a model’s pre-trained knowledge, a RAG system fetches real-time information using semantic search and metadata filtering. This means you get responses that are more accurate, context-aware, and free from hallucinations.
If you’re already using PostgreSQL or considering it for your stack, adding RAG capabilities is easier than you might think. Open-source PostgreSQL extensions like pgvector, pgai, and pgvectorscale streamline the process, allowing you to build intelligent applications without reinventing the wheel. Let’s take a quick look at how these extensions supercharge your database:
Pgvector: Bringing vector search to PostgreSQL
pgvector enables PostgreSQL to handle vector data, making it possible to perform fast and efficient similarity searches. Whether you’re working with embeddings from text, images, or other data types, pgvector helps you find the most relevant results by comparing vectors. This is a game-changer for AI applications that need high-speed, accurate retrieval.
Pgai: AI capabilities for your database
pgai takes PostgreSQL to the next level by integrating with top AI models from Cohere, OpenAI, Anthropic, and Ollama. With a unified interface, pgai allows you to seamlessly query multiple AI models while providing powerful utilities like a built-in vectorizer to automate the process of converting data into embeddings.
Understanding Amazon Bedrock
Amazon Bedrock is AWS’s fully managed service for building and deploying AI models—without worrying about infrastructure, maintenance, or third-party dependencies. Whether you need natural language processing, machine learning, or advanced data analytics, Bedrock gives you access to powerful AI capabilities right out of the box.
With Bedrock, you can create and deploy AI models, including RAG systems, using a range of pre-trained models and frameworks. It’s built for scalability, so you can focus on developing AI-driven applications without the complexity of managing resources.
Here are some of the key features of Amazon Bedrock:
- Access to top AI models: Bedrock supports popular models like Hugging Face Transformers and PyTorch-based LLMs.
- Seamless deployment & scaling: Easily deploy, manage, and scale AI models without handling infrastructure.
- Support for major frameworks: It works with TensorFlow, JAX, PyTorch, and more.
- Optimized workflows: Bedrock provides prebuilt workflows to fine-tune and deploy models efficiently.
- Real-time inferencing: It enables AI-driven applications to generate instant responses.
- GPU acceleration: It leverages high-performance compute resources for faster model execution.
- Deep AWS integration: As expected, Amazon Bedrock works with AWS Lambda, AWS Glue, AWS Lake Formation, and other key AWS services.
In this article, we will explore how to use Amazon Bedrock to build a RAG system using Anthropic and PostgreSQL.
Implementing RAG Using PostgreSQL, Amazon Bedrock, and Anthropic
Before getting started, ensure you have access to Amazon Bedrock and Anthropic, along with a working installation of PostgreSQL. You'll also need the pgvector, pgai, and pgvectorscale extensions installed to enable vector search and AI capabilities.
Step 1. Set up PostgreSQL with extensions
You can install PostgreSQL with the required extensions locally using Docker. Alternatively, you can sign up for Timescale Cloud to set up a free PostgreSQL instance with the necessary extensions. We'll use Timescale Cloud for simplicity.
Sign up at timescale.com and launch a free PostgreSQL cluster with the ‘AI and Vector’ features enabled.
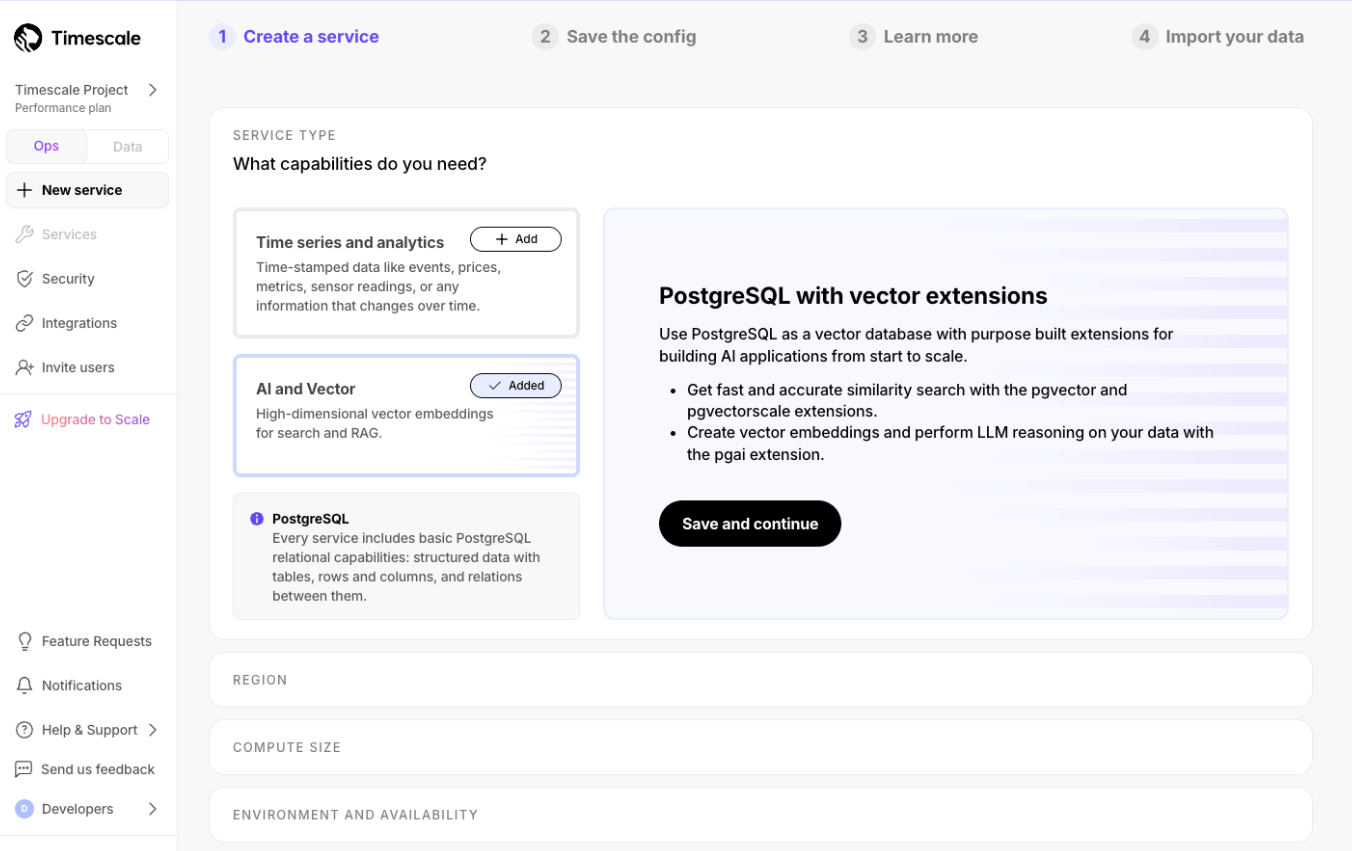
Once you’ve launched the service, save the connection configuration.
Step 2. Get access to models on Amazon Bedrock
Next, head over to Amazon Bedrock and sign in with your AWS account. Once logged in, click on ‘Model Access’. You’ll need access to an embedding model and Claude 3.5 Sonnet. If you don’t have access to a model, you can click on ‘Available to Request’ to submit a request.
For this tutorial, we’ll use Amazon’s Titan Text model.
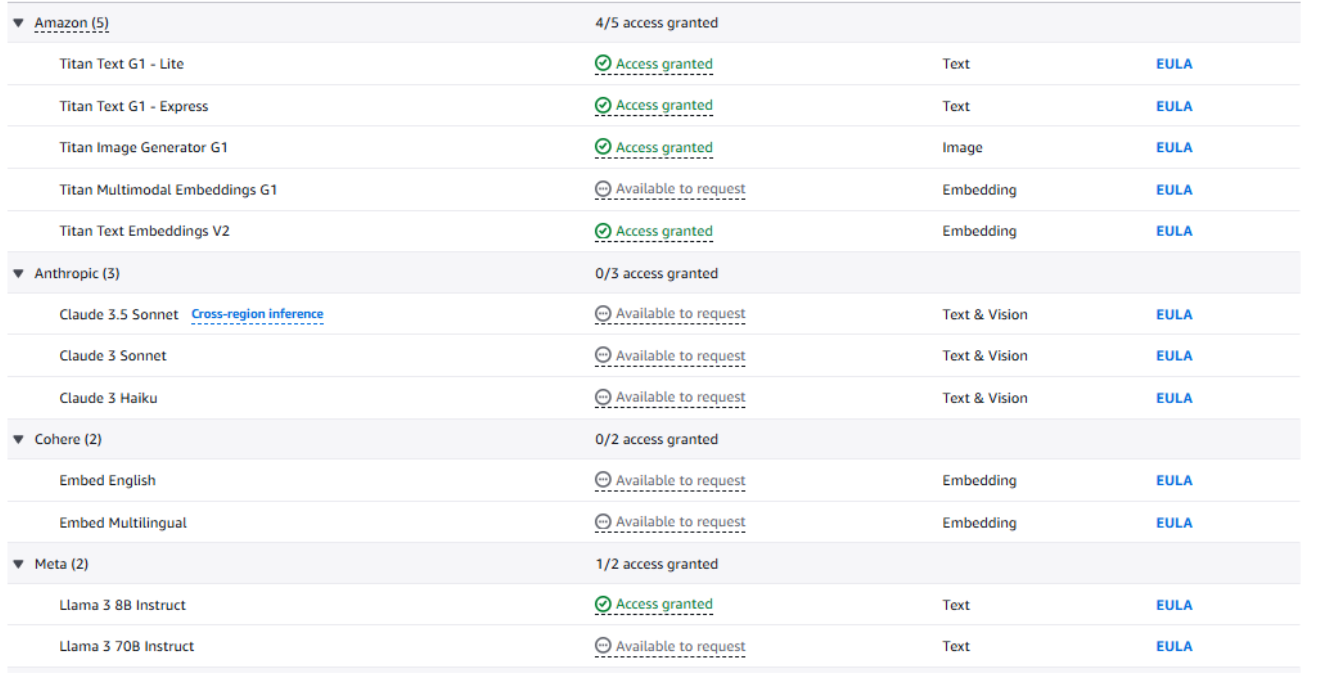
You'll also need the standard AWS credentials to access any AWS service:
- AWS Access Key ID
- AWS Secret Access Key
- AWS Default Region
Step 3. Install and import libraries
In a Jupyter Notebook environment, install the required libraries:
!pip install -q anthropic psycopg2 boto3 python-dotenv
Once installed, import them:
import psycopg2
From dotenv import load_dotenv
import anthropic
import os
import boto3
from botocore.exceptions import NoCredentialsError
import json
import base64Step 4. Connect AWS client
Ensure that you have your environment variables set up.
# Set up AWS credentials
os.environ['AWS_ACCESS_KEY_ID'] = os.getenv('<your aws access key id>')
os.environ['AWS_SECRET_ACCESS_KEY'] = os.getenv('<your secret key>')
os.environ['AWS_DEFAULT_REGION'] = 'your_aws_region'
Now let’s connect to AWS using boto3:
try:
aws_client = boto3.client('bedrock-runtime', region_name='ap-south-1')
print("AWS Client created successfully!")
except NoCredentialsError as e:
print("Error:", e)Step 5. Set up Anthropic client
You can get access to Anthropic in two ways: either request access on Bedrock or sign up at Anthropic directly and get an API key. We will use the latter approach.
Once you have the API key, save it in an environment variable and use it to connect to Anthropic:
os.environ['AWS_ACCESS_KEY_ID'] = 'your_anthropic_api_key'
anthropic_client = anthropic.Anthropic(
api_key = ANTHROPIC_API_KEY,
)
Step 6. Create table
Now, let’s connect to the PostgreSQL instance and create a table to store our dataset. We’ll also enable the pgai, pgvector, and pgvectorscale extensions.
DB_URL = "<POSTGRESQL_DB_CONNECTION_STRING>"
conn = psycopg2.connect(DB_URL)
conn.autocommit = True
dimensions = 512
# Enable pgvector, pgai and pgvectorscale
pgvector = """CREATE EXTENSION IF NOT EXISTS vector"""
pgai = """CREATE EXTENSION IF NOT EXISTS ai CASCADE"""
pgvectorscale = """CREATE EXTENSION IF NOT EXISTS vectorscale CASCADE"""
with conn.cursor() as cursor:
cursor.execute(pgvector)
cursor.execute(pgvectorscale)
cursor.execute(pgai)
cur.execute(f"""
CREATE TABLE movie (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
overview TEXT,
genres TEXT,
producer TEXT,
cast TEXT
);
""")Step 7. Generate embeddings
We will now use pgai’s vectorizer to autogenerate embeddings using the AWS Bedrock Titan Embed Text model.
with conn.cursor() as cur:
cur.execute("""
SELECT ai.create_vectorizer(
'movie'::regclass,
destination => 'movie_embedding_store',
embedding => ai.embedding_litellm(
'bedrock/amazon.titan-embed-text-v1',
512,
api_key_name => %s,
extra_options => '{"aws_secret_access_key": "' || %s || '", "aws_region_name": "' || %s || '"}'::jsonb
),
chunking => ai.chunking_character_text_splitter('overview', 1000, 0),
formatting => ai.formatting_python_template('$chunk')
);
""", (os.getenv('AWS_ACCESS_KEY_ID'), os.getenv('AWS_SECRET_ACCESS_KEY'), os.getenv('AWS_DEFAULT_REGION')))The embeddings generated by this vectorizer will be stored in a separate table called movie_embedding_store.
Step 8. Load dataset
We will now load the Cohere/movies dataset, generate embeddings, and store them in the PostgreSQL table rag_data. Below is one row from the dataset:
[
{
"id": 1,
"title": "Avatar",
"overview": "In the 22nd century, a paraplegic Marine is dispatched to the moon Pandora on a unique mission, but becomes torn between following orders and protecting an alien civilization.",
"genres": "Action, Adventure, Fantasy, Science Fiction",
"producer": "Ingenious Film Partners, Twentieth Century Fox Film Corporation, Dune Entertainment, Lightstorm Entertainment",
"cast": "Sam Worthington as Jake Sully, Zoe Saldana as Neytiri, Sigourney Weaver as Dr. Grace Augustine, Stephen Lang as Col. Quaritch, Michelle Rodriguez as Trudy Chacon, Giovanni Ribisi as Selfridge, Joel David Moore as Norm Spellman, CCH Pounder as Moat, Wes Studi as Eytukan, Laz Alonso as Tsu'Tey, Dileep Rao as Dr. Max Patel, Matt Gerald as Lyle Wainfleet, Sean Anthony Moran as Private Fike, Jason Whyte as Cryo Vault Med Tech, Scott Lawrence as Venture Star Crew Chief, Kelly Kilgour as Lock Up Trooper, James Patrick Pitt as Shuttle Pilot, Sean Patrick Murphy as Shuttle Co-Pilot, Peter Dillon as Shuttle Crew Chief, Kevin Dorman as Tractor Operator / Troupe, Kelson Henderson as Dragon Gunship Pilot, David Van Horn as Dragon Gunship Gunner, Jacob Tomuri as Dragon Gunship Navigator, Michael Blain-Rozgay as Suit #1, Jon Curry as Suit #2, Luke Hawker as Ambient Room Tech, Woody Schultz as Ambient Room Tech / Troupe, Peter Mensah as Horse Clan Leader, Sonia Yee as Link Room Tech, Jahnel Curfman as Basketball Avatar / Troupe, Ilram Choi as Basketball Avatar, Kyla Warren as Na'vi Child, Lisa Roumain as Troupe, Debra Wilson as Troupe, Chris Mala as Troupe, Taylor Kibby as Troupe, Jodie Landau as Troupe, Julie Lamm as Troupe, Cullen B. Madden as Troupe, Joseph Brady Madden as Troupe, Frankie Torres as Troupe, Austin Wilson as Troupe, Sara Wilson as Troupe, Tamica Washington-Miller as Troupe, Lucy Briant as Op Center Staff, Nathan Meister as Op Center Staff, Gerry Blair as Op Center Staff, Matthew Chamberlain as Op Center Staff, Paul Yates as Op Center Staff, Wray Wilson as Op Center Duty Officer, James Gaylyn as Op Center Staff, Melvin Leno Clark III as Dancer, Carvon Futrell as Dancer, Brandon Jelkes as Dancer, Micah Moch as Dancer, Hanniyah Muhammad as Dancer, Christopher Nolen as Dancer, Christa Oliver as Dancer, April Marie Thomas as Dancer, Bravita A. Threatt as Dancer, Colin Bleasdale as Mining Chief (uncredited), Mike Bodnar as Veteran Miner (uncredited), Matt Clayton as Richard (uncredited), Nicole Dionne as Nav'i (uncredited), Jamie Harrison as Trooper (uncredited), Allan Henry as Trooper (uncredited), Anthony Ingruber as Ground Technician (uncredited), Ashley Jeffery as Flight Crew Mechanic (uncredited), Dean Knowsley as Samson Pilot, Joseph Mika-Hunt as Trooper (uncredited), Terry Notary as Banshee (uncredited), Kai Pantano as Soldier (uncredited), Logan Pithyou as Blast Technician (uncredited), Stuart Pollock as Vindum Raah (uncredited), Raja as Hero (uncredited), Gareth Ruck as Ops Centreworker (uncredited), Rhian Sheehan as Engineer (uncredited), T. J. Storm as Col. Quaritch's Mech Suit (uncredited), Jodie Taylor as Female Marine (uncredited), Alicia Vela-Bailey as Ikran Clan Leader (uncredited), Richard Whiteside as Geologist (uncredited), Nikie Zambo as Na'vi (uncredited), Julene Renee as Ambient Room Tech / Troupe"
}
]
You can simply use the load_dataset utility provided by pgai to load the Cohere/movies dataset from Hugging Face and insert it into PostgreSQL. Embeddings will be generated by the vectorizer as the data is loaded.
with conn.cursor() as cur:
cur.execute("""
SELECT ai.load_dataset(
'Cohere/movies', -- Dataset name on Hugging Face
table_name => 'movie', -- Name of the existing table in PostgreSQL
schema_name => 'public', -- Schema where the table exists
split => 'train', -- Split of the dataset to load (e.g., train/test/validation)
if_table_exists => 'append' -- Append data to the existing table
);
""")Step 9. Similarity search
Next, we'll add a helper function to perform a similarity search using a query vector. This function will retrieve relevant context by comparing the stored embeddings against the query vector, ordering the results by distance score, and fetching the most relevant matches. These retrieved results will then be used to augment the LLM's generation in the next step.
# Query similar movies using pgvector
def query_similar_movies(query, top_k=3, distance_metric="<->"):
query_embedding = str(generate_embedding(query))
with conn.cursor() as cur:
# Construct SQL query for nearest neighbors
cur.execute(
f"""
SELECT id, title, overview, genres, producer, cast, embedding {distance_metric} %s AS similarity
FROM movie
ORDER BY similarity ASC
LIMIT %s
""",
(query_embedding, top_k)
)
results = cur.fetchall()
return resultsIn the above query, the default similarity search metric has been set to L2 distance. You can also use Euclidean distance or Cosine similarity, depending on your use case.
Step 10. Generation function
Let’s now write a function that performs the ‘generation’ step in RAG. Here, we’ll use pgai’s ai.anthropic_generate function, which allows us to directly call the Anthropic Claude 3.5 Sonnet model within a PostgreSQL query.
def llm_response(query: str, context: list):
context_str = "\n".join(context)
api_key = userdata.get("ANTHROPIC_API_KEY")
with conn.cursor() as cur:
cur.execute(f"SET ai.anthropic_api_key TO '{api_key}';")
cur.execute(
"""
SELECT jsonb_extract_path_text(
ai.anthropic_generate(
'claude-3-5-sonnet-20241022',
jsonb_build_array(
jsonb_build_object(
'role', 'user',
'content',
concat(
'You are a human-friendly answer generator from the given query and context. Respond with only the answer - detailed.\n\n',
'Query: ', %s, '\n',
'Context: ', %s
)
)
)
),
'content', '0', 'text'
);
""",
(query, context_str)
)
result = cur.fetchone()
return result[0] if result and result[0] else "No response generated."Step 11. Putting it all together
We will now test the RAG workflow above with a query. Here’s how you can do it:
query = "what was the cast of Avatar?"
# Query similar movies from PostgreSQL
similar_movies = query_similar_movies(query)
# Prepare the context using the retrieved similar movies in list format
context = ["\n".join(map(str, item)) for item in similar_movies]
# Get the response from the LLM
response = llm_response(query, context)
# Display the response
print("LLM Response:")
print(response)You will get results like:
LLM Response:The main cast of Avatar (2009) includes:- Sam Worthington as Jake Sully- Zoe Saldana as Neytiri- Sigourney Weaver as Dr. Grace Augustine- Stephen Lang as Col. Quaritch- Michelle Rodriguez as Trudy Chacon- Giovanni Ribisi as Selfridge- Joel David Moore as Norm Spellman- CCH Pounder as Moat- Wes Studi as Eytukan- Laz Alonso as Tsu'Tey- Dileep Rao as Dr. Max PatelThese actors played the primary characters in the film, with Sam Worthington and Zoe Saldana as the lead protagonists, Sigourney Weaver and Stephen Lang in crucial supporting roles, and the others forming the essential supporting cast that helped bring the world of Pandora to life.The LLM generates responses using the context retrieved from the similarity search. By following the approach outlined above, you can easily build RAG applications using Anthropic Claude and PostgreSQL on Amazon Bedrock.
Next Steps
In this tutorial, we explored how to build a Retrieval-Augmented Generation (RAG) system using Amazon Bedrock, Anthropic, and PostgreSQL. By leveraging AWS Bedrock’s embedding models, Anthropic’s Claude 3.5 Sonnet, and PostgreSQL’s vector search extensions (pgvector, pgai, and pgvectorscale), we created a robust RAG system—without relying on external frameworks or additional infrastructure.
To start building clever RAG systems today, install the open-source pgvector and pgai extensions in your PostgreSQL database—or get started for free with Timescale Cloud (no credit card required)!