When working with unstructured data, such as customer feedback, product reviews, or support queries, you need to enrich your data with additional details. For instance, with product reviews, you may want to add customer demographics, product details, or review sentiment. With support queries, you might want to categorize issues, extract key topics, or analyze customer sentiment.
Data enrichment is the process of enhancing raw or unstructured data by adding additional context to make it more actionable. This is typically done using APIs, machine learning models, or third-party data providers to append missing details, standardize formats, and add contextual insights.
In this article, we’ll walk you through automating unstructured data enrichment in PostgreSQL using OpenAI’s GPT-4o model. We will use a hotel reviews dataset, where reviews are in the form of unstructured text, and enrich them with sentiment scores, extracted keywords, and vector embeddings. By the end, you'll know how to set up an automated pipeline that processes and enhances text data in real time—ensuring every new entry is optimized for search, analysis, and deeper insights.
What Is Data Enrichment?
Data enrichment is all about enhancing raw data by adding relevant, high-quality information from external or internal sources. This process improves the accuracy of your applications and deepens the insights you can extract from your data. Ultimately, enrichment keeps your database up-to-date, actionable, and optimized for analytics.
With the rise of large language models (LLMs) and vision-language models (VLMs), we now have powerful tools to extract valuable insights from massive volumes of unstructured data—whether it's text, images, or audio generated by users.
When should you enrich your data?
Data enrichment can happen in two ways: real-time or batch mode.
- Real-time enrichment happens as data enters your system, using triggers, stored procedures, or API calls. This ensures that your data is clean and enriched from the start.
- Batch enrichment happens periodically, using scheduled jobs or external pipelines to update your dataset.
Ideally, real-time enrichment is the way to go. By enriching data as it arrives, you maintain high-quality information from the beginning—rather than treating it as an afterthought.
Approach to Automating Data Enrichment in PostgreSQL
PostgreSQL is the most popular database among developers—and for good reason. When combined with open-source extensions like pgai, pgvector, and pgvectorscale, it transforms into a powerful AI-ready database, outshining others in building AI-driven applications.
In this article, we’ll use these extensions to automate data enrichment in PostgreSQL. To demonstrate the process, we will use a hotel reviews dataset, where reviews are provided as unstructured text, and enhance them by extracting hotel names, customer sentiment, and keywords used by customers to describe their stay. We will also generate embedding for each review so that we can easily perform similarity search on this data.
Before we start with the implementation, let’s take a quick look at pgvector, pgai, and pgvectorscale extensions, and their key features:
Pgvector: High-dimensional vector Search in PostgreSQL
pgvector enables PostgreSQL to store and search high-dimensional vector embeddings within PostgreSQL. This is essential for AI-driven enrichment tasks like similarity search, classification, and recommendation systems. You can use it to categorize text, detect duplicate records, or find semantically similar data.
Pgai: AI & machine learning integrated into queries
pgai integrates AI and machine learning models directly into PostgreSQL queries, allowing for on-the-fly embedding creation and model completions right within your database. With its vectorizer feature, pgai automates the generation and synchronization of vector embeddings for your data, as well as the process of creating indexes for faster search.
Pgvectorscale: Scalable & efficient AI workloads
pgvectorscale is built for high-performance, cost-efficient vector search, making it ideal for large-scale AI applications. It introduces the StreamingDiskANN index, inspired by Microsoft's DiskANN algorithm, which stores part of the index on disk to handle large workloads efficiently. Additionally, it features Statistical Binary Quantization (SBQ)—a cutting-edge compression technique developed by Timescale researchers—to reduce storage requirements while maintaining high accuracy.
We’ll use these extensions to create a trigger that automates the data enrichment process in PostgreSQL, ensuring your data is always optimized and AI-ready. Let’s dive in.
Our Workflow
For this tutorial, we’ll use a hotel reviews dataset. Here’s the approach we’ll follow:
- Enable AI and vector extensions: Activate the required PostgreSQL extensions (pgai, pgvector, and pgvectorscale) to support AI-driven enrichment and vector storage.
- Create a hotel reviews table: Define a structured table to store reviews along with metadata like hotel names, reviewers, and ratings.
- Implement an enrichment function: Use OpenAI’s API to extract sentiment and keywords from review texts.
- Automate enrichment with triggers: Set up a trigger to process new reviews automatically upon insertion.
- Vectorize review data: Store semantic embeddings using pgvector to enable similarity searches and advanced queries.
By the end of this tutorial, you’ll have an automated workflow that enriches hotel review data in real time.
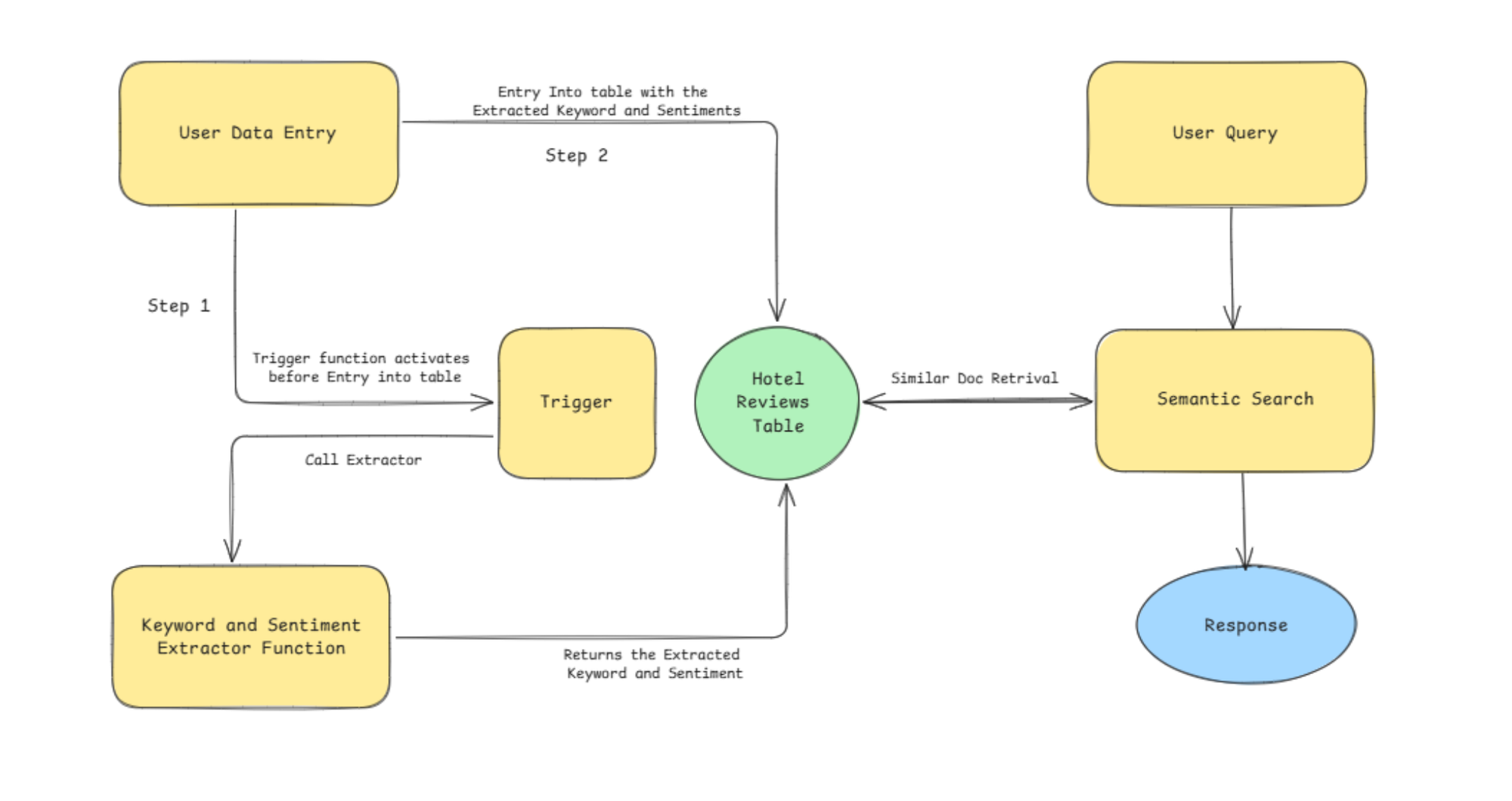
Implementation Steps
Let’s start with the implementation.
Step 1. Set up PostgreSQL database
To enable AI-powered data enrichment, you’ll need a PostgreSQL database with the pgai, pgvector, and pgvectorscale extensions. You can install them using Docker or opt for a free PostgreSQL instance from Timescale Cloud. For simplicity, we’ll go with the latter:
Database setup
- Create a PostgreSQL instance: Sign up for Timescale Cloud and deploy a new instance, ensuring that you choose the AI and Vector option.
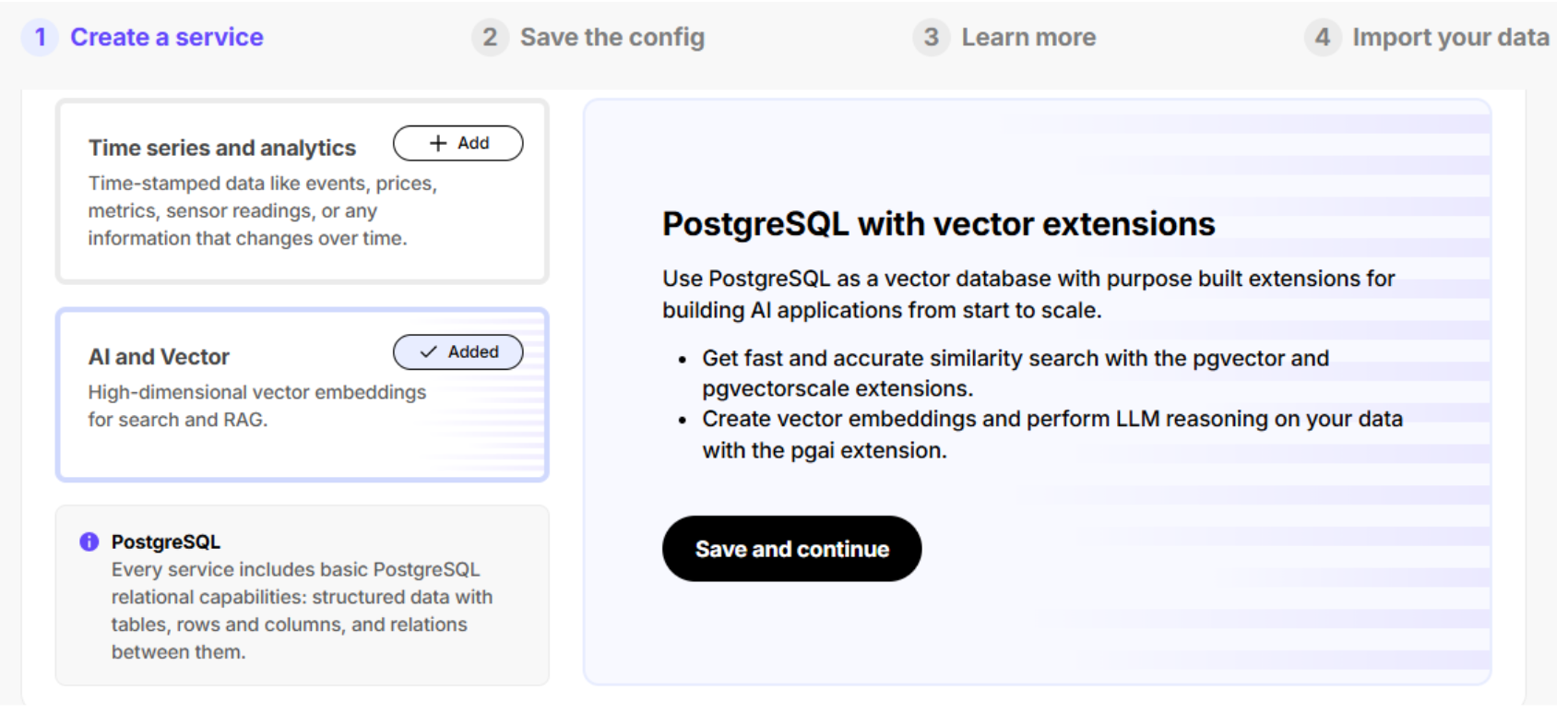
- Enable AI and Vector extensions: During setup, activate pgvector, pgai, and pgvectorscale to ensure full support for AI-driven enrichment.
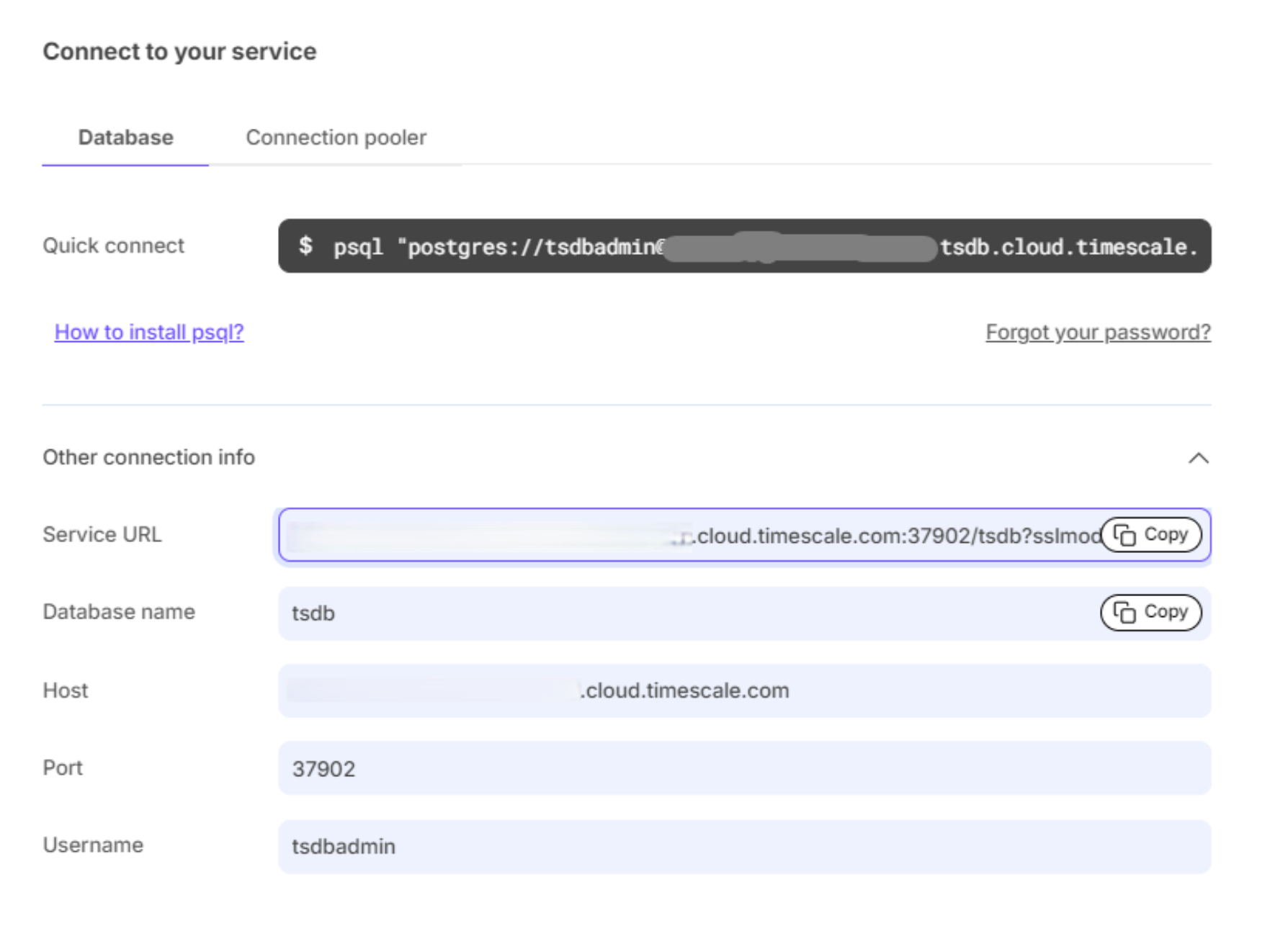
- Retrieve credentials: Once your instance is up and running, copy the connection details from the cloud dashboard. You’ll need these to connect from your SQL editor.
Step 2. Set Up PopSQL
For this tutorial, we’ll use PopSQL as our remote SQL editor. To set it up, follow these steps:
- Download and install PopSQL: Get the latest version from PopSQL’s website.
- Log in to PopSQL: Open the application and sign in.
- Connect to your database
- Navigate to the Connect Portal in PopSQL.
- Select PostgreSQL as the database type.
- Enter the connection details from your Timescale Cloud instance.
- Test the connection: Run a simple query (
SELECT NOW();) to ensure everything is set up correctly.
Once connected, you’re ready to start executing queries on your PostgreSQL instance.
Enable pgai, pgvector, and pgvectorscale extensions in PostgreSQL
To enable the pgai, pgvector, and pgvectorscale extensions, run the following SQL query:
CREATE EXTENSION IF NOT EXISTS ai CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS vectorscale CASCADE;Set up OpenAI API key
Since the code relies on OpenAI’s API, you must configure the API key before using it. You can do so by running the following command:
SET ai.openai_api_key TO '<your openai api key>';
Step 3. Create a table for the dataset
The next step is creating a table to store hotel reviews. In the table named hotel_reviews, we’ll include an ID as the primary key, a review_text field for the actual review, and other fields, such as hotel_name, reviewer, and rating to capture details about the reviewer and their rating.
Additionally, we’ll add a sentiment field to store the sentiment of the review and a keywords array to hold extracted keywords from the review. The sentiment and keywords will be automatically extracted using AI-powered trigger functions. You can create the table using the following command:
CREATE TABLE IF NOT EXISTS hotel_reviews (
id SERIAL PRIMARY KEY,
review_text TEXT,
hotel_name TEXT,
reviewer TEXT,
rating INTEGER,
sentiment TEXT,
keywords TEXT[]
);Step 4. Data enrichment function
To enrich the review data, let’s create a function named enrich_review_data(). This function uses the pgai function openai_chat_complete() to send the review text to OpenAI's GPT-4o model and extracts sentiment and keywords.
When a new review is inserted or updated, the function calls the OpenAI API, retrieves a JSON response containing the sentiment and keywords, and assigns these values to the respective fields in the table. It also logs the AI response for debugging. Here’s how you can create the function:
CREATE OR REPLACE FUNCTION enrich_review_data()
RETURNS TRIGGER AS $$
DECLARE
metadata JSONB;
BEGIN
-- Call OpenAI API and capture response
SELECT ai.openai_chat_complete(
'gpt-4o',
jsonb_build_array(
jsonb_build_object('role', 'system', 'content',
'Extract sentiment and keywords from the following review. Always return a valid JSON object with this format:
{ "sentiment": "positive", "keywords": ["amazing", "friendly", "location"] }'),
jsonb_build_object('role', 'user', 'content', 'Review: ' || NEW.review_text)
)
) INTO metadata;
-- Log the full AI response for debugging
RAISE NOTICE 'AI Response: %', metadata;
-- Extract the JSON response from the assistant's message
metadata := metadata->'choices'->0->'message'->>'content';
-- Ensure it's valid JSON
BEGIN
metadata := metadata::JSONB;
EXCEPTION WHEN others THEN
RAISE EXCEPTION 'Failed to parse AI response as JSONB: %', metadata;
END;
-- Assign values
NEW.sentiment := metadata->>'sentiment';
-- Correct conversion of JSON array to PostgreSQL text[]
NEW.keywords := ARRAY(
SELECT jsonb_array_elements_text(metadata->'keywords')
);
RETURN NEW;
END;
$$ LANGUAGE plpgsql;Step 5. Create a PostgreSQL trigger
With the function in place, let’s create a trigger named before_insert_review to ensure that the enrich_review_data() function is executed automatically before any new review is inserted. This guarantees that every review is enriched with sentiment and keyword data the moment it is added to the database. You can create it using the following command:
CREATE TRIGGER before_insert_review
BEFORE INSERT ON hotel_reviews
FOR EACH ROW
EXECUTE FUNCTION enrich_review_data();Step 6. Insert hotel review data
Now that everything is set up, we can start inserting hotel reviews into the table. Each review will include details such as the review text, hotel name, reviewer’s name, and rating. When these records are inserted, the trigger automatically calls the enrich_review_data() function, which enhances the review by adding sentiment and keyword analysis. Here’s an example of how you can insert multiple reviews:
INSERT INTO hotel_reviews (review_text, hotel_name, reviewer, rating) VALUES
('The rooms at The Plaza Hotel were immaculate, and the staff went above and beyond to ensure our stay was exceptional. The location is perfect for exploring the city.', 'The Plaza Hotel', 'Emily', 5),
('Had a pleasant stay at The Ritz-Carlton. The service was top-notch, and the amenities were excellent. However, the dining options were a bit limited.', 'The Ritz-Carlton', 'Michael', 4),
('The view from our room at Grand Hyatt was breathtaking. The room was spacious and clean, but the check-in process was slow.', 'Grand Hyatt', 'Sophia', 4),
('Enjoyed my stay at Hilton Garden Inn. The staff was friendly, and the rooms were comfortable. The breakfast buffet could use more variety.', 'Hilton Garden Inn', 'James', 4),
('The location of Marriott Marquis is unbeatable. The rooms were modern and well-maintained. However, the noise from the street was quite disruptive at night.', 'Marriott Marquis', 'Olivia', 3),
('Had a wonderful experience at Four Seasons Resort. The spa services were exceptional, and the dining was exquisite. Highly recommend for a relaxing getaway.', 'Four Seasons Resort', 'Liam', 5),
('The room at Holiday Inn Express was clean and comfortable. The complimentary breakfast was a nice touch, though the options were limited.', 'Holiday Inn Express', 'Ava', 3),
('Stayed at The Westin for a business trip. The conference facilities were top-notch, and the staff was attentive. The room service menu could be expanded.', 'The Westin', 'Noah', 4),
('The ambiance at The Langham was luxurious, and the service was impeccable. The only downside was the high cost of parking.', 'The Langham', 'Isabella', 4),
('The boutique feel of Kimpton Hotel was charming. The evening wine hour was a pleasant surprise. The room was a bit small but well-appointed.', 'Kimpton Hotel', 'Ethan', 4),
('The historic charm of The Brown Palace Hotel is undeniable. The afternoon tea service was delightful. Some areas of the hotel could use updating.', 'The Brown Palace Hotel', 'Mia', 3),
('The beachfront location of The Del was perfect. The rooms were spacious, and the on-site dining was excellent. The resort fee seemed a bit excessive.', 'Hotel del Coronado', 'Lucas', 4),
('The modern design of W Hotel was impressive. The rooftop bar offered stunning views of the city. The music from the bar was loud even in our room.', 'W Hotel', 'Amelia', 3),
('The service at The Peninsula was outstanding. The room was luxurious, and the spa treatments were rejuvenating. Truly a five-star experience.', 'The Peninsula', 'Mason', 5),
('The location of Hyatt Regency was convenient for our conference. The rooms were clean, and the staff was helpful. The elevators were quite slow.', 'Hyatt Regency', 'Harper', 3),
('The rustic charm of The Lodge at Woodloch was perfect for a weekend retreat. The wellness programs were excellent, and the food was healthy and delicious.', 'The Lodge at Woodloch', 'Benjamin', 5),
('The proximity of Courtyard by Marriott to local attractions was great. The rooms were standard but clean. The lack of an on-site restaurant was inconvenient.', 'Courtyard by Marriott', 'Evelyn', 3),
('The opulence of The St. Regis was evident in every detail. The butler service was a unique touch, and the room was exquisitely furnished.', 'The St. Regis', 'Elijah', 5),
('The eco-friendly initiatives at 1 Hotel were impressive. The decor was chic and sustainable. The check-in process was a bit disorganized.', '1 Hotel', 'Abigail', 4),
('The family-friendly atmosphere at Disney''s Grand Floridian Resort made our vacation memorable. The character breakfasts were a hit with the kids.', 'Disney''s Grand Floridian Resort', 'William', 5);
This INSERT statement adds multiple rows of hotel reviews to the hotel_reviews table. Each review includes details such as the review text, hotel name, reviewer’s name, and rating. When these records are inserted, the trigger we set earlier (before_insert_review) automatically calls the enrich_review_data() function, which enhances the review with sentiment and keyword analysis.
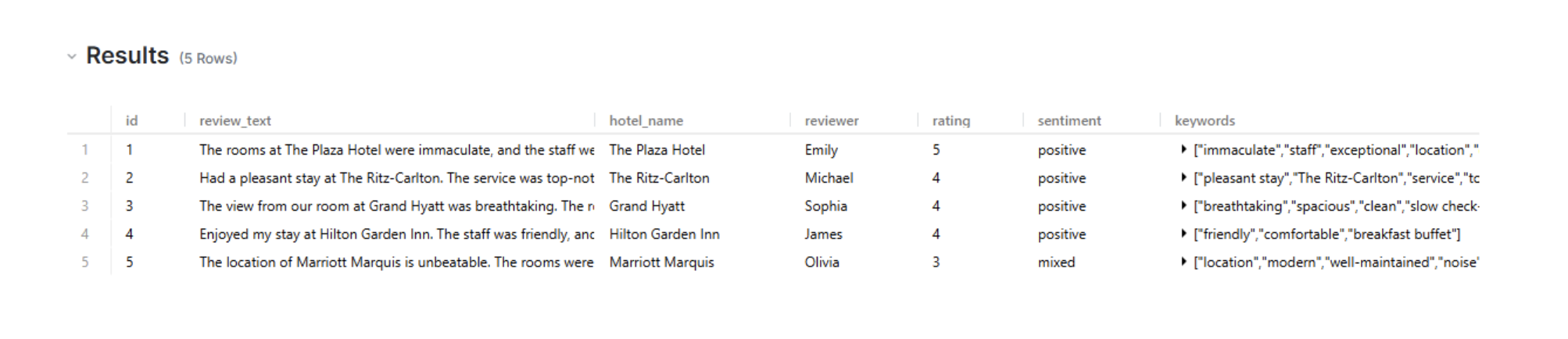
View the results here.
Step 7. Automatically enrich with embeddings
We’ll further enrich the data using vector embeddings, enabling similarity searches when needed. Pgai provides a simple yet powerful way to achieve this through its vectorizer utility. The pgai vectorizer automates embedding creation and also adds a hierarchical navigable small worlds (HNSW) index for faster similarity searches.
In the code below, the ai.create_vectorizer function is applied to the hotel_reviews table, and the embeddings are stored in a new table called hotel_reviews_embeddings_vectorized. To ensure that long reviews are processed effectively, the ai.chunking_recursive_character_text_splitter function breaks the review_text field into smaller chunks. This approach helps maintain context without exceeding token limits.
SELECT ai.create_vectorizer(
'hotel_reviews'::regclass,
destination => 'hotel_reviews_embeddings_vectorized',
embedding => ai.embedding_openai('text-embedding-3-small', 1536),
chunking => ai.chunking_recursive_character_text_splitter('review_text'),
formatting => ai.formatting_python_template(
'$hotel_name - Review: $chunk - Keywords: $keywords - Sentiment: $sentiment'
),
indexing => ai.indexing_hnsw( opclass => ‘vector_cosine_ops’ )
);To keep the embeddings meaningful, the ai.formatting_python_template function structures each chunk to include the hotel name, review text, extracted keywords, and sentiment.
We’ll also create an HNSW index to speed up similarity searches. HNSW is a graph-based algorithm designed for approximate nearest neighbor (ANN) searches. It builds a multi-layer graph where:
- The top layers contain fewer nodes, enabling coarse-grained navigation.
- Lower layers offer fine-grained navigation for more precise searches.
The search process starts at the top layer and moves downward, leveraging the small-world graph structure to efficiently locate neighbors. HNSW delivers both high search speed and accuracy, making it ideal for large datasets.
Once you execute the query, the pgai vectorizer will automatically generate embeddings as new data is inserted into the table.
You can view the results here.
Step 8. Perform semantic search on the enriched table (optional)
Now we can easily perform semantic search on the table as well. We will embed the user query using the ai.openai_embed function, and then compare the resulting vector against the precomputed embeddings stored in hotel_reviews_embeddings_vectorized. We’ll use the cosine distance metric ( <#> operator) to calculate the similarity (distance) between vectors.
WITH query_embedding AS (
SELECT ai.openai_embed('text-embedding-3-small', '<Your Query>', api_key=>'<Openai_Api_Key>') AS embedding
)
SELECT
h.hotel_name,
h.reviewer,
h.rating,
h.review_text,
h.sentiment,
h.keywords,
t.embedding <#> (SELECT embedding FROM query_embedding) AS distance
FROM hotel_reviews_embeddings_vectorized t
LEFT JOIN hotel_reviews h ON t.id = h.id
WHERE
h.sentiment = '<your searching sentiment - say positive>' -- Filter by sentiment
AND h.keywords && ARRAY[<keyword1>, <keyword2>]::TEXT[] -- Match at least one keyword
ORDER BY distance
LIMIT <No. Of Results you want>;Example query
Let’s run an example query. We’ll search for hotels that offer luxury amenities, excellent service, and a relaxing spa. Additionally, we can apply filters using keywords and sentiment derived from the enrichment process.
WITH query_embedding AS (
SELECT ai.openai_embed(
'text-embedding-3-small',
'Looking for a luxury hotel with impeccable service, top-notch amenities, and a relaxing spa. Prefer a peaceful ambiance and elegant interiors.',
api_key => '<OPENAI_API_KEY>'
) AS embedding
)
SELECT
h.hotel_name,
h.reviewer,
h.rating,
h.review_text,
h.sentiment,
h.keywords,
t.embedding <#> (SELECT embedding FROM query_embedding) AS distance
FROM hotel_reviews_embeddings_vectorized t
LEFT JOIN hotel_reviews h ON t.id = h.id
WHERE
h.sentiment = 'positive' -- Filter for positive sentiment
AND h.keywords && ARRAY['wonderful', 'spa']::TEXT[] -- Match at least one keyword
ORDER BY distance
LIMIT 4;Result
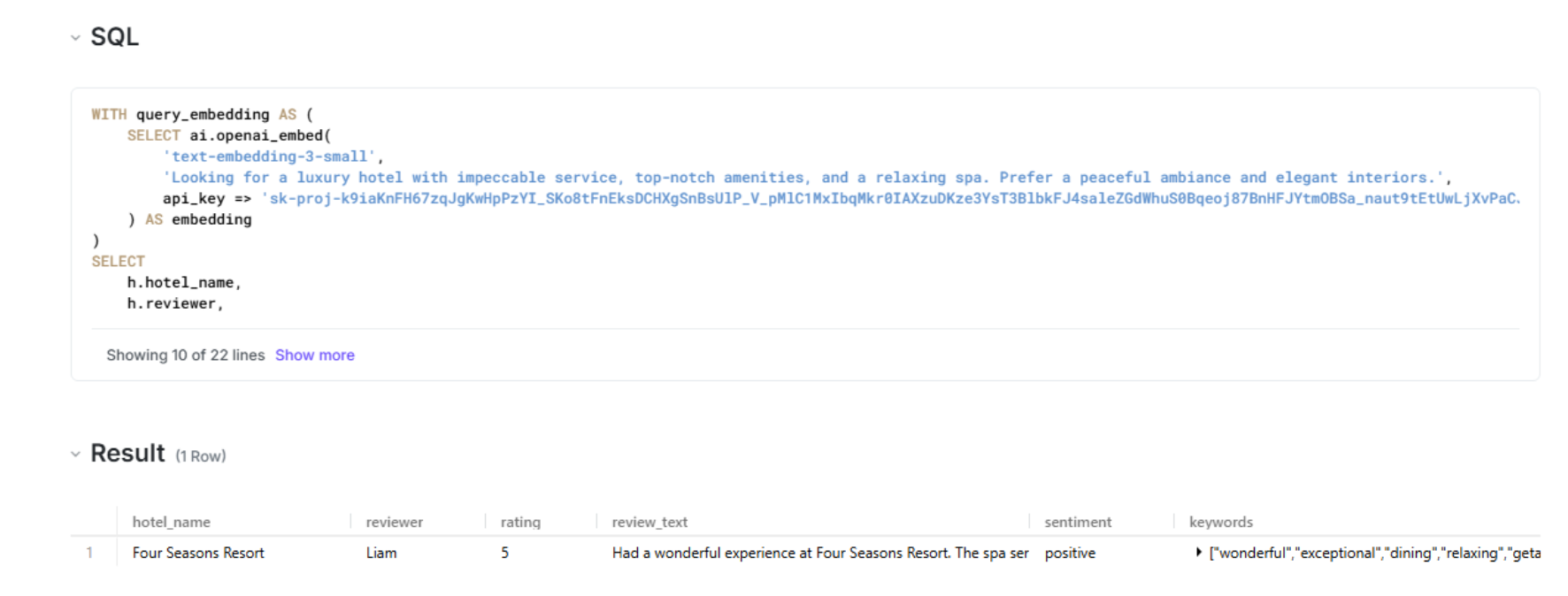
You can also find the results here.
[
{
"hotel_name": "Four Seasons Resort",
"reviewer": "Liam",
"rating": 5,
"review_text": "Had a wonderful experience at Four Seasons Resort. The spa services were exceptional, and the dining was exquisite. Highly recommend for a relaxing getaway.",
"sentiment": "positive",
"keywords": [
"wonderful",
"exceptional",
"dining",
"relaxing",
"getaway"
],
"distance": -0.5081281661987305
}
]
We now have a system that automates data enrichment within PostgreSQL and OpenAI’s GPT-4o model. By integrating pgvector, pgai, and pgvectorscale, we built a real-time processing pipeline that extracts sentiment and keywords from hotel reviews using OpenAI’s GPT-4o model. Our system ensures that every new review is automatically processed and enriched.
Additionally, we used pgai’s vectorizer to automate vector embedding generation so that we could perform a similarity search on this data. You can use a similar approach to enrich unstructured data in your application and make it more actionable.
Next Steps
Data enrichment is a powerful way to enhance the quality of your data. By automating enrichment for both structured and unstructured data, you can extract deeper insights and make your data more actionable.
With OpenAI embeddings, pgvector, pgai, pgvectorscale, and triggers, you can easily automate data enrichment within your PostgreSQL database. Additionally, pgai’s vectorizer utility ensures that embeddings are generated automatically, keeping your data ready for semantic search-powered applications.
Ready to get started? Install PostgreSQL with pgai, pgvector, and pgvectorscale locally, or launch a free PostgreSQL cluster on Timescale Cloud.