Vector databases manage high-dimensional numerical data that powers AI applications. These specialized databases process vectorized content like text, images, and embeddings used by machine learning models.
A well-configured vector database infrastructure becomes crucial as query volumes and data grow. Query latency differences—like 50 ms versus 200 ms—can make or break your AI application's performance requirements.
When considering your application's production deployment, vector database costs directly affect performance and deployment options. Choosing between managed services and self-hosted databases can also impact infrastructure costs and engineering resources. Analyzing these costs early in the deployment phase helps predict budget requirements and prevent architectural compromises.
This article evaluates Pinecone—one of the leading vector databases—and its pricing model. We will analyze three key areas:
- Pinecone's pricing structure and optimization configurations for different workload types
- Performance and cost comparisons with PostgreSQL and pgvector implementations
- Selection criteria for choosing the optimal vector database based on your workload characteristics
What Is Pinecone?
Pinecone is a managed vector database service built specifically for AI workloads. Unlike general-purpose databases with vector extensions like PostgreSQL with pgvector, Pinecone focuses exclusively on vector data processing. The service handles all configuration and maintenance tasks but operates as a closed-source system. This means you cannot modify or extend the underlying database engine to match specific requirements while you get a fully managed service.
Vector databases serve as specialized data stores for AI applications. They manage two critical AI workloads:
- Training data storage: They maintain vectorized datasets used to train machine learning models. These vectors represent features extracted from raw data like text, images, or audio.
- RAG systems: They store reference materials for retrieval-augmented generation (RAG), where AI models access relevant information during generation. The database efficiently retrieves contextual information that helps models generate more accurate and factual responses.
The core function of vector databases is optimizing vector operations. These databases process high-dimensional numerical arrays through specialized algorithms like nearest neighbor search and cosine similarity calculations. This optimization enables fast and accurate similarity matching between vectors—a fundamental requirement for many AI applications. Traditional databases struggle with these operations due to the unique characteristics of vector data and the computational complexity of similarity searches.
For example, vector databases store document embeddings and perform rapid similarity searches to find relevant context when implementing RAG systems. The speed and accuracy of these similarity searches directly impact the quality of AI-generated responses. A well-optimized vector database can search through millions of vectors in milliseconds, making real-time AI applications possible.
How Does Pinecone Pricing Work?
Pinecone offers a range of plans to suit different needs. The Starter Plan is free and limited to one index and one project. The Standard Plan starts at $0.096/hour and is suitable for production applications with various pod types like p1 and s1 for performance and storage optimization, respectively.
For larger-scale applications, the Enterprise Plan provides custom pricing with additional support and features. Performance-optimized pods prioritize speed, while storage-optimized pods focus on capacity, allowing users to choose based on their specific requirements.
Your selection between these tiers depends on your workload characteristics, such as whether you prioritize data storage capacity or query performance.
Pinecone's infrastructure operates at a fixed 90 % recall rate—you cannot adjust this parameter even if your application requires higher accuracy. This contrasts with open-source solutions like PostgreSQL, where you can fine-tune recall rates, index parameters, and other performance settings to match your specific requirements. This limitation can be a significant constraint for applications requiring 99 % recall rates.
This pricing and configuration model may work for standard use cases. However, applications requiring specific optimizations or higher recall rates must evaluate whether the fixed parameters align with their performance requirements. For example, recommendation systems might need higher recall rates for accurate suggestions, while semantic search applications prioritize query speed over perfect accuracy.
The fixed nature of these configurations also impacts scaling decisions. As your data and query volumes grow, you cannot gradually adjust parameters to optimize costs. Instead, you must choose between the two predefined tiers, which might lead to over-provisioning or performance compromises.
How Does Pinecone Pricing Stack Up?
Cost benchmarks reveal significant differences between Pinecone and PostgreSQL-based solutions. When comparing monthly costs for Pinecone vs. PostgreSQL, for a database storing 50M embeddings:
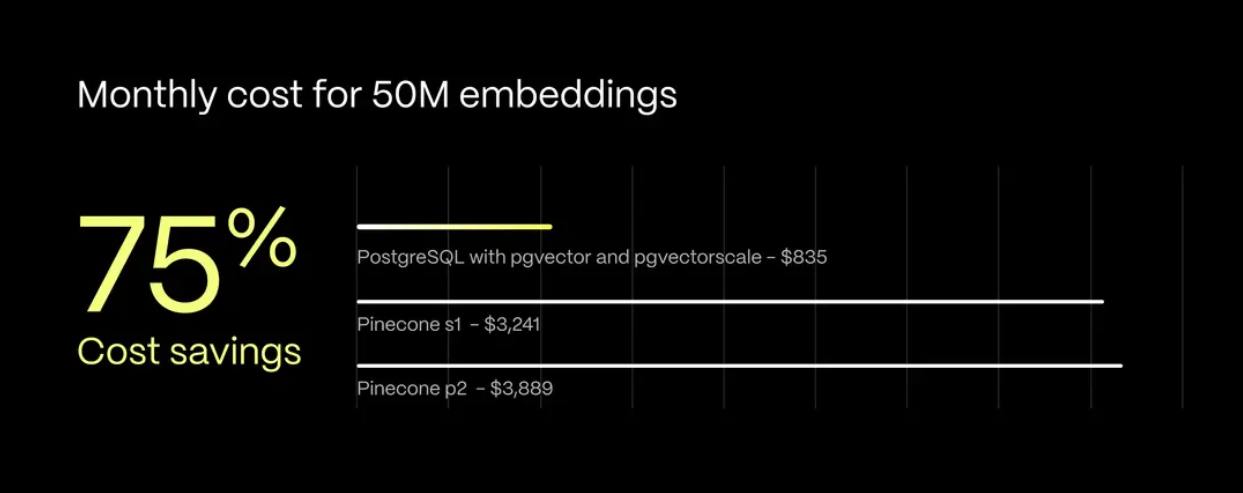
This pricing structure means PostgreSQL solutions offer a 75 % cost reduction for similar workloads. The monthly savings of $2,400-$3,000 can significantly impact your operational budget, especially for startups and growing applications. These costs become more pronounced as your data volume increases.
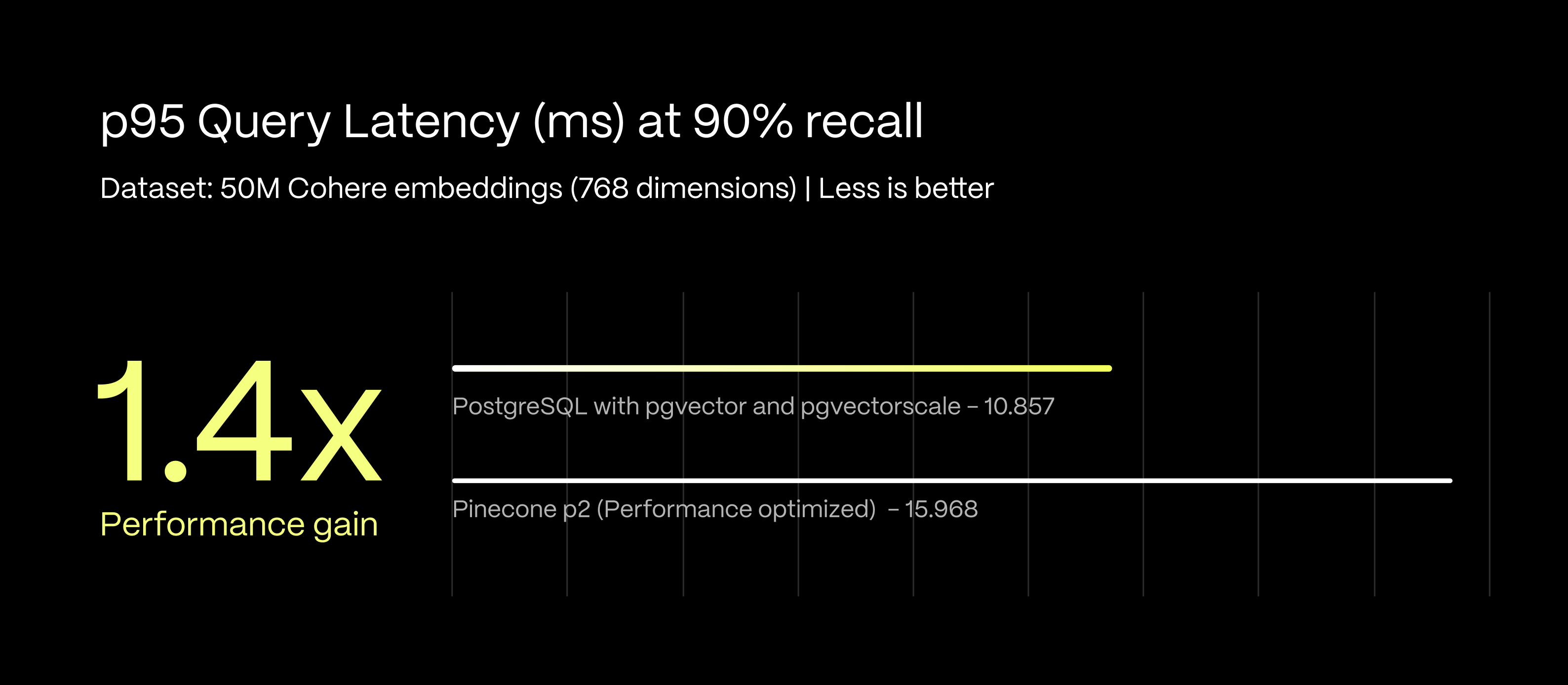
Performance benchmarks at 90 % recall rate show unexpected results:
- PostgreSQL achieves 10.86 ms P95 query latency.
- Pinecone's performance-optimized tier shows 15.97 ms P95 query latency.
- This represents a 1.4x performance advantage for PostgreSQL. Faster query response from PostgreSQL means your applications can handle higher throughput while maintaining consistent response times.
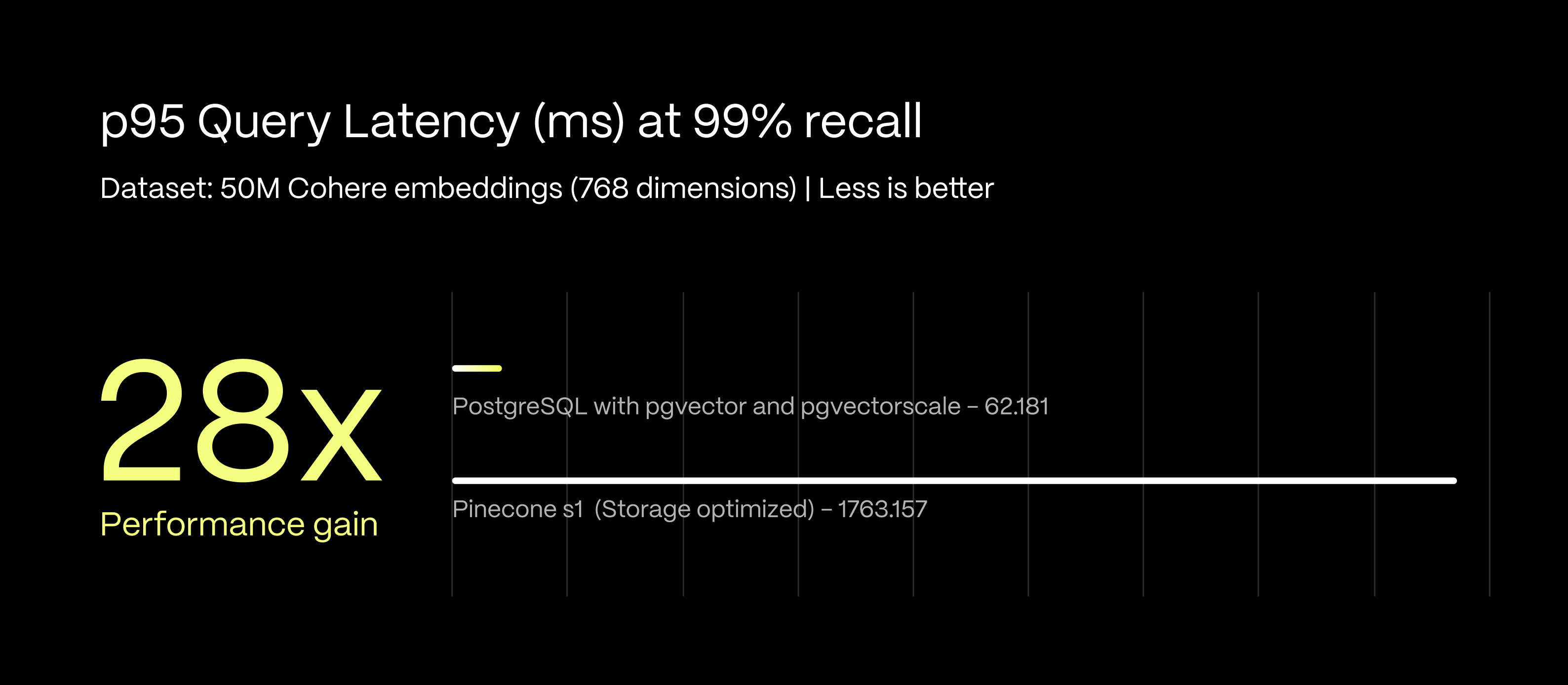
At 99 % recall rate, the performance gap widens dramatically:
- PostgreSQL maintains 62.18 ms P95 query latency.
- Pinecone's storage-optimized tier reaches 1,763.16 ms P95 query latency.
- PostgreSQL demonstrates a 28x performance advantage. This difference becomes critical for applications that require high accuracy. A 1.7-second query latency can severely impact user experience and application responsiveness.
These benchmarks used a 50M Cohere embeddings dataset with 768 dimensions—a realistic scenario for production AI applications. PostgreSQL with pgvector and pgvectorscale (developed by Timescale) delivers superior performance at a 75 % lower cost than Pinecone. The open-source solution delivers better results in a number of aspects:
- Lower query latency across all tested recall rates
- Better cost efficiency for production workloads
- More consistent performance as recall requirements increase
- Greater flexibility in tuning and optimization
PostgreSQL with pgvector and Timescale's vector extensions offers a more cost-effective solution for most production deployments without compromising performance. The combination of lower costs and better performance makes it particularly attractive for scalable AI applications where budget and latency matter.
Is Pinecone Right For Your Budget?
Selecting a vector database requires evaluating both technical capabilities and operational requirements. Beyond performance benchmarks, factors like management overhead, scaling capabilities, and total cost of ownership significantly impact the success of AI applications.
Core considerations
Vector databases handle critical operations in AI systems—from similarity searches to data retrieval for large language models. The choice of database infrastructure affects several aspects:
- Query performance and accuracy
- Operational complexity and maintenance
- Cost scaling with data growth
- Team resource allocation
Here's a comprehensive comparison across key decision factors:
Pinecone advantages
Pinecone provides a fully managed service that reduces operational overhead by handling infrastructure complexities. The service manages all backend systems, from deployment to maintenance, allowing development teams to focus on application logic rather than database operations. Built-in monitoring tools and professional support provide stability assurance for production deployments.
These managed features particularly benefit teams without dedicated database expertise. Scaling becomes straightforward as Pinecone handles capacity planning and infrastructure expansion. You don't need to worry about node management, replication configuration, or backup strategies.
However, these conveniences come with significant constraints. The fixed monthly costs can strain budgets, especially for growing applications. The inability to tune performance parameters like recall rates limits optimization options. You're locked into Pinecone's decisions about system configuration and optimization strategies.
PostgreSQL with vector extensions
PostgreSQL with pgvector offers a more flexible and economical approach to vector search. The open-source nature provides complete control over your database infrastructure. You can tune every aspect of the system, from index parameters to query optimization settings. The active PostgreSQL community offers extensive resources and support for troubleshooting and optimization.
Timescale's open-source vector extensions—pgai and pgvectorscale—turn PostgreSQL into a high-performance vector database. While pgai brings AI workflows into PostgreSQL and allows developers to automate embedding creation and synchronization with a single line of SQL via pgai Vectorizer, pgvectorscale adds advanced indexing capabilities to pgvector, resulting in speed, a simplified AI stack, and convenience, thanks to SQL familiarity.
The primary consideration is operational responsibility. Your team needs expertise in PostgreSQL administration, covering setup, maintenance, monitoring, and scaling. While the community provides excellent support, you'll need to manage your infrastructure and handle any issues that arise actively.
Scaling with Timescale
Timescale builds on PostgreSQL's foundation to address your scaling needs. These optimized data structures have proven effective in production environments, managing petabytes of data with billions of daily records. This scalability maintains PostgreSQL's performance advantages while adding enterprise-grade reliability.
Also, Timescale's cloud service bridges the gap between self-hosted PostgreSQL and managed services like Pinecone. You get the flexibility and cost advantages of PostgreSQL with reduced operational overhead. The service handles infrastructure management while preserving your ability to tune and optimize the database.
With Timescale Cloud, you can quickly access pgvector, pgvectorscale, and pgai—extensions that turn PostgreSQL into an easy-to-use and high-performance vector database, plus a fully managed cloud database experience.
Making the decision
The optimal choice depends on your specific circumstances. Larger teams with strong database expertise might leverage PostgreSQL's superior performance and cost advantages. Those prioritizing rapid deployment and minimal operational overhead might accept Pinecone's premium pricing. Timescale Cloud offers a middle ground, particularly for applications expecting significant scale, while enabling developers to keep all their AI workflows within PostgreSQL and supercharge it for RAG, semantic search, and vector search.
Consider your team's technical capabilities, growth projections, and budget constraints. The cost differences between options could fund other aspects of your AI infrastructure, while management requirements affect team allocation and hiring needs.
Conclusion
If your team is building AI applications, choosing a vector database significantly affects both performance and costs. As we've analyzed, while Pinecone offers a managed solution, your team could perform better at lower costs with open-source alternatives. The decision impacts your current deployment and future scaling capabilities and budget allocation.
Our benchmarks have shown that PostgreSQL (with pgvector and Timescale's extensions) outperforms Pinecone across key metrics:
- 28x faster query response at 99 % recall rates, enabling more responsive AI applications
- 75 % reduction in monthly infrastructure costs, freeing the budget for other development needs
- Greater control over performance tuning, allowing optimization for specific workload patterns
- Flexible scaling options that adapt to your application's growth
For most production deployments, PostgreSQL with pgvector and Timescale's open-source stack provides the optimal balance of performance and cost. The open-source solution efficiently handles typical AI workloads—from similarity searches to RAG system implementations.
If your team needs managed infrastructure while maintaining PostgreSQL's advantages, Timescale Cloud extends these benefits with enterprise-grade scalability. You retain the cost advantages of open-source while reducing operational overhead.
You can evaluate Timescale Cloud capabilities for your specific use case through a free trial here. The platform offers a practical way to test performance metrics against your workloads without committing to an entire deployment.