Jina AI is announcing new models in its family of state-of-the-art reranker models, now available on AWS Sagemaker and Hugging Face: jina-reranker-v1-turbo-en and jina-reranker-v1-tiny-en. These models prioritize speed and size while maintaining high performance on standard benchmarks, offering a faster and more memory-efficient reranking process for environments where response time and resource use are critical.




Reranker Turbo and Tiny are optimized for blazing-fast response times in information retrieval applications. Like our embedding models, they use the JinaBERT architecture, a variant of the BERT architecture enhanced with a symmetric bidirectional variant of ALiBi. This architecture enables support for long text sequences, with our models accepting up to 8,192 tokens, ideal for deep analysis of larger documents and complex queries requiring detailed language understanding.
The Turbo and Tiny models draw on insights gained from Jina Reranker v1. Reranking can be a major bottleneck for information retrieval applications. Traditional search applications are a very mature technology whose performance is well-understood. Rerankers add a great deal of precision to text-based retrieval, but AI models are large and can be slow and expensive to run.
Many users would prefer a smaller, faster, cheaper model, even if it comes at some cost to accuracy. Having a single goal – reranking search results – makes it possible to streamline the model and bring users competitive performance in much more compact models. By using fewer hidden layers, we speed up processing and reduce model size. These models cost less to run, and the greater speed makes them more useful for applications that can't tolerate much latency, while retaining nearly all of the performance of larger models.
In this article, we'll show you the architecture of Reranker Turbo and Reranker Tiny, measure its performance, and show you how to get started with them.
Streamlined Architecture
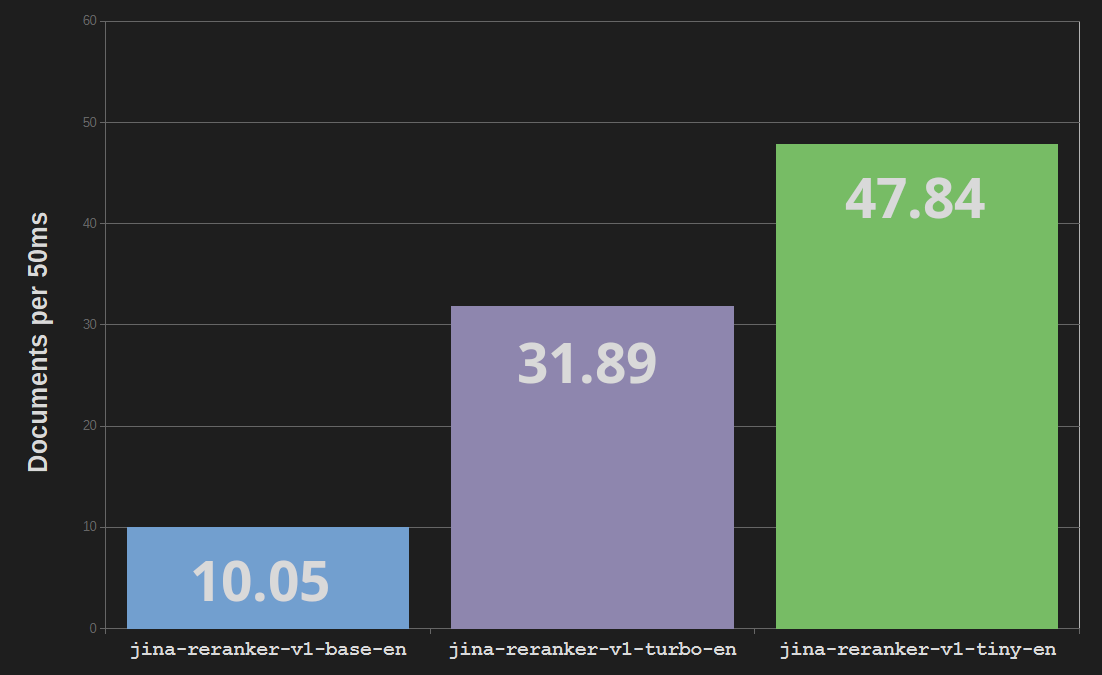
Jine Reranker Turbo (jina-reranker-v1-turbo-en) uses a six-layer architecture, with a total of 37.8 million parameters, in contrast to the 137 million parameters and twelve layers of the base reranker model jina-reranker-v1-base-en. This represents a reduction in model size of three-quarters and as much as a tripling of processing speed.
Reranker Tiny (jina-reranker-v1-tiny-en) uses four layers with 33 million parameters, providing even greater parallel processing and faster speeds – almost five times as fast as the base Reranker model – while saving 13% of memory costs over the Turbo model.
Knowledge Distillation
We've trained Reranker Turbo and Tiny using knowledge distillation. This is a technique for using an existing AI model to train another one to match its behavior. Instead of using external data sources, we use an existing model to generate data for training. We used the Jina Reranker base model to rank collections of documents and then used those results to train both Turbo and Tiny. This way, we can bring much more data into the training process because we aren't limited by available real-world data.
This is a bit like a student learning from a teacher: The already trained, high-performance model – the Jina Reranker Base model – "teaches" the untrained Jina Turbo and Jina Tiny models by generating new training data. This technique is widely used to create small models from large ones. At its best, the difference in task performance between the "teacher" model and the "student" can be very small.
Evaluation on BEIR
The benefits of streamlining and knowledge distillation come at relatively little cost to performance quality. On the BEIR benchmark for information retrieval, jina-reranker-v1-turbo-en scores just under 95% of the accuracy of jina-reranker-v1-base-en, and jina-reranker-v1-tiny-en scores 92.5% of the base model's score.
All Jina Reranker models are competitive with other popular reranker models, most of which have much larger sizes.
| Model | BEIR Score (NDCC@10) | Parameters |
|---|---|---|
| Jina Reranker models | ||
jina-reranker-v1-base-en |
52.45 | 137M |
jina-reranker-v1-turbo-en |
49.60 | 38M |
jina-reranker-v1-tiny-en |
48.54 | 33M |
| Other reranking models | ||
mxbai-rerank-base-v1 |
49.19 | 184M |
mxbai-rerank-xsmall-v1 |
48.80 | 71M |
ms-marco-MiniLM-L-6-v2 |
48.64 | 23M |
bge-reranker-base |
47.89 | 278M |
ms-marco-MiniLM-L-4-v2 |
47.81 | 19M |
NDCC@10: Scores calculated using Normalized Discounted Cumulative Gain for the top 10 results.
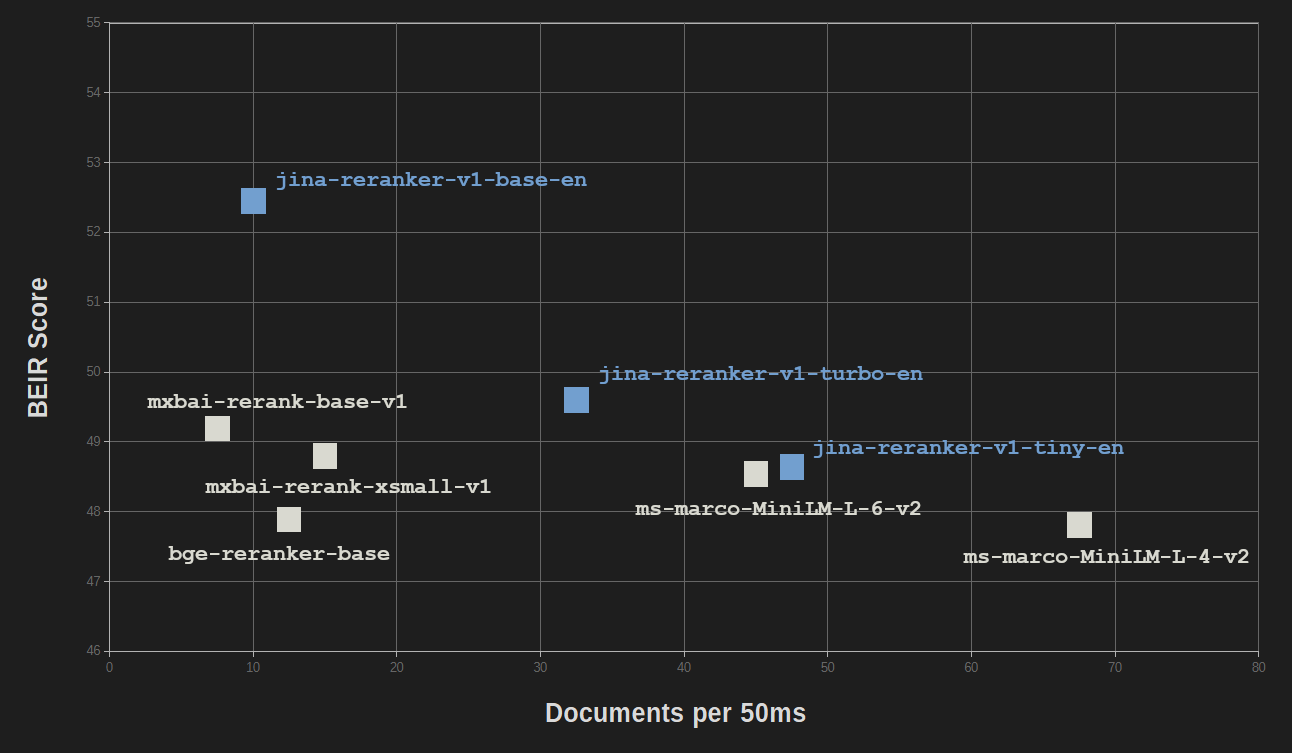
Only MiniLM-L6 (ms-marco-MiniLM-L-6-v2) and MiniLM-L4 (ms-marco-MiniLM-L-4-v2) have comparable sizes and speeds, with jina-reranker-v1-turbo-en and jina-reranker-v1-tiny-en performing comparably or significantly better.
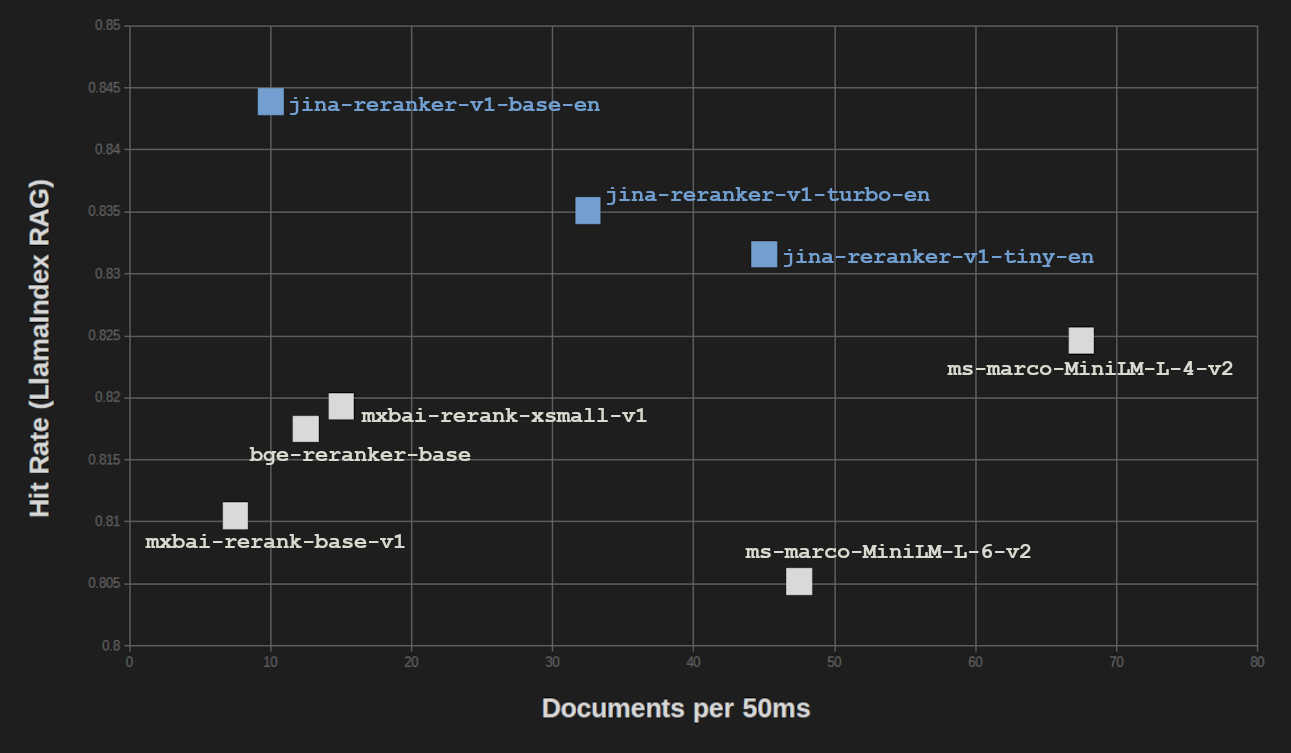
We get similar results on the LlamaIndex RAG Benchmark. We tested all three Jina Rerankers in a RAG setup using three embedding models for vector search (jina-embeddings-v2-base-en, bge-base-en-v1.5, and Cohere-embed-english-v3.0) and averaged the scores.
| Reranker Model | Avg. Hit Rate | Avg. MRR |
|---|---|---|
| Jina Reranker models | ||
jina-reranker-v1-base-en |
0.8439 | 0.7006 |
jina-reranker-v1-turbo-en |
0.8351 | 0.6498 |
jina-reranker-v1-tiny-en |
0.8316 | 0.6761 |
| Other reranking models | ||
mxbai-rerank-base-v1 |
0.8105 | 0.6583 |
mxbai-rerank-xsmall-v1 |
0.8193 | 0.6673 |
ms-marco-MiniLM-L-6-v2 |
0.8052 | 0.6121 |
bge-reranker-base |
0.8175 | 0.6480 |
ms-marco-MiniLM-L-4-v2 |
0.8246 | 0.6354 |
MRR: Mean Reciprocal Rank
For retrieval-augmented generation (RAG) tasks, losses in result quality are even less than on the BEIR pure information retrieval benchmark. And when RAG performance is put up next to processing speed, we see that only ms-marco-MiniLM-L-4-v2 provides significantly more throughput, at a significant cost in result quality.
Cost Savings on AWS
Using Reranker Turbo and Reranker Tiny provides large savings for AWS and Azure users who pay for memory usage and CPU time. Although the degree of savings varies for different use cases, the roughly 75% reduction in memory usage alone directly corresponds to a 75% savings for cloud systems charging for memory.
Furthermore, the faster throughput means that you can run more queries on cheaper AWS instances.
Getting Started
Jina Reranker models are easy to use and integrate into your applications and workflow. To get started, you can visit the Reranker API page to see how to use our service and get 1 million free tokens of access to try it out yourself.

Our models are also available in AWS SageMaker. For more information, see our tutorial on how to set up a retrieval-augmented generation system in AWS.

Jina Reranker models are also available for download under the Apache 2.0 license from Hugging Face:
Contact Us
Jina AI remains committed to bringing the highest quality models to enterprises at competitive prices. Reranker Turbo and Tiny bring state-of-the-art AI to cloud-based information retrieval applications at a large reduction in cost. When every gigabyte of memory and processing instance counts, we're here to help you stretch your cloud computing budget.
Contact us via our website or our Discord channel to share your feedback and stay up-to-date with our latest models.

